Linux
Linux 内核最初只是由芬兰人林纳斯·托瓦兹(Linus Torvalds)在赫尔辛基大学上学时出于个人爱好而编写的。 Linux 是一套免费使用和自由传播的类 Unix 操作系统,是一个基于 POSIX 和 UNIX 的多用户、多任务、支持多线程和多 CPU 的操作系统。 Linux 能运行主要的 UNIX 工具软件、应用程序和网络协议。它支持 32 位和 64 位硬件。Linux 继承了 Unix 以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。
- Linux 基础
- Linux 应用
- Zookeeper 安装
- FTP(File Transfer Protocol)介绍
- CI 一整套服务
- LDAP 安装和配置
- Kubernets(K8S) 使用
- Hadoop 安装和配置
- Gitlab 安装和配置
- Rinetd:一个用户端口重定向工具
- Linux 实践
- Error: ENOSPC: System limit for number of file watchers reached
- 使用Nginx转发TCP/UDP
- Linux系统编写Systemd Service实践
- Linux安装rinetd实现TCP/UDP端口转发
- 使用Nginx进行TCP/UDP端口转发
- linux系统中rsync+inotify实现服务器之间文件实时同步
- rsync 用法教程
- Centos 6无法使用yum解决办法(centos6停止更新)
- Nginx配置中不同请求匹配不同请求
- 使用 flock 文件锁解决 crontab 冲突问题
- Ubuntu扩展 /dev/mapper/ubuntu--vg-ubuntu--lv空间
- 搭建RTMP直播流服务器实现直播
- FRP使用
- ubuntu 防止SSH暴力登录攻击
- AES五种加密模式(CBC、ECB、CTR、OCF、CFB)
Linux 基础
Linux 内核最初只是由芬兰人林纳斯·托瓦兹(Linus Torvalds)在赫尔辛基大学上学时出于个人爱好而编写的。 Linux 是一套免费使用和自由传播的类 Unix 操作系统,是一个基于 POSIX 和 UNIX 的多用户、多任务、支持多线程和多 CPU 的操作系统。 Linux 能运行主要的 UNIX 工具软件、应用程序和网络协议。它支持 32 位和 64 位硬件。Linux 继承了 Unix 以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。
Bash 常用命令
基础常用命令
某个命令 --h,对这个命令进行解释某个命令 --help,解释这个命令(更详细)man某个命令,文档式解释这个命令(更更详细)(执行该命令后,还可以按/+关键字进行查询结果的搜索)Ctrl + c,结束命令TAB键,自动补全命令(按一次自动补全,连续按两次,提示所有以输入开头字母的所有命令)键盘上下键,输入临近的历史命令history,查看所有的历史命令Ctrl + r,进入历史命令的搜索功能模式clear,清除屏幕里面的所有命令pwd,显示当前目录路径(常用)firefox&,最后后面的 & 符号,表示使用后台方式打开 Firefox,然后显示该进程的 PID 值jobs,查看后台运行的程序列表ifconfig,查看内网 IP 等信息(常用)curl ifconfig.me,查看外网 IP 信息curl ip.cn,查看外网 IP 信息locate 搜索关键字,快速搜索系统文件/文件夹(类似 Windows 上的 everything 索引式搜索)(常用)updatedb,配合上面的 locate,给 locate 的索引更新(locate 默认是一天更新一次索引)(常用)
date,查看系统时间(常用)date -s20080103,设置日期(常用)date -s18:24,设置时间,如果要同时更改 BIOS 时间,再执行hwclock --systohc(常用)
cal,在终端中查看日历,肯定没有农历显示的uptime,查看系统已经运行了多久,当前有几个用户等信息(常用)cat 文件路名,显示文件内容(属于打印语句)cat -n 文件名,显示文件,并每一行内容都编号more 文件名,用分页的方式查看文件内容(按 space 翻下一页,按 Ctrl + B 返回上页)less文件名,用分页的方式查看文件内容(带上下翻页)- 按 j 向下移动,按 k 向上移动
- 按 / 后,输入要查找的字符串内容,可以对文件进行向下查询,如果存在多个结果可以按 n 调到下一个结果出
- 按 ? 后,输入要查找的字符串内容,可以对文件进行向上查询,如果存在多个结果可以按 n 调到下一个结果出
shutdownshutdown -hnow,立即关机shutdown -h+10,10 分钟后关机shutdown -h23:30,23:30 关机shutdown -rnew,立即重启
poweroff,立即关机(常用)reboot,立即重启(常用)zip mytest.zip /opt/test/,把 /opt 目录下的 test/ 目录进行压缩,压缩成一个名叫 mytest 的 zip 文件unzip mytest.zip,对 mytest.zip 这个文件进行解压,解压到当前所在目录unzip mytest.zip -d /opt/setups/,对 mytest.zip 这个文件进行解压,解压到 /opt/setups/ 目录下
tar -cvf mytest.tar mytest/,对 mytest/ 目录进行归档处理(归档和压缩不一样)tar -xvf mytest.tar,释放 mytest.tar 这个归档文件,释放到当前目录tar -xvf mytest.tar -C /opt/setups/,释放 mytest.tar 这个归档文件,释放到 /opt/setups/ 目录下
last,显示最近登录的帐户及时间lastlog,显示系统所有用户各自在最近登录的记录,如果没有登录过的用户会显示 从未登陆过ls,列出当前目录下的所有没有隐藏的文件 / 文件夹。ls -a,列出包括以.号开头的隐藏文件 / 文件夹(也就是所有文件)ls -R,显示出目录下以及其所有子目录的文件 / 文件夹(递归地方式,不显示隐藏的文件)ls -a -R,显示出目录下以及其所有子目录的文件 / 文件夹(递归地方式,显示隐藏的文件)ls -al,列出目录下所有文件(包含隐藏)的权限、所有者、文件大小、修改时间及名称(也就是显示详细信息)ls -ld 目录名,显示该目录的基本信息ls -t,依照文件最后修改时间的顺序列出文件名。ls -F,列出当前目录下的文件名及其类型。以 / 结尾表示为目录名,以 * 结尾表示为可执行文件,以 @ 结尾表示为符号连接ls -lg,同上,并显示出文件的所有者工作组名。ls -lh,查看文件夹类文件详细信息,文件大小,文件修改时间ls /opt | head -5,显示 opt 目录下前 5 条记录ls -l | grep '.jar',查找当前目录下所有 jar 文件ls -l /opt |grep "^-"|wc -l,统计 opt 目录下文件的个数,不会递归统计ls -lR /opt |grep "^-"|wc -l,统计 opt 目录下文件的个数,会递归统计ls -l /opt |grep "^d"|wc -l,统计 opt 目录下目录的个数,不会递归统计ls -lR /opt |grep "^d"|wc -l,统计 opt 目录下目录的个数,会递归统计ls -lR /opt |grep "js"|wc -l,统计 opt 目录下 js 文件的个数,会递归统计ls -l,列出目录下所有文件的权限、所有者、文件大小、修改时间及名称(也就是显示详细信息,不显示隐藏文件)。显示出来的效果如下:
-rwxr-xr-x. 1 root root 4096 3月 26 10:57,其中最前面的 - 表示这是一个普通文件
lrwxrwxrwx. 1 root root 4096 3月 26 10:57,其中最前面的 l 表示这是一个链接文件,类似 Windows 的快捷方式
drwxr-xr-x. 5 root root 4096 3月 26 10:57,其中最前面的 d 表示这是一个目录
cd,目录切换cd ..,改变目录位置至当前目录的父目录(上级目录)。cd ~,改变目录位置至用户登录时的工作目录。cd 回车,回到家目录cd -,上一个工作目录cd dir1/,改变目录位置至 dir1 目录下。cd ~user,改变目录位置至用户的工作目录。cd ../user,改变目录位置至相对路径user的目录下。cd /../..,改变目录位置至绝对路径的目录位置下。
cp 源文件 目标文件,复制文件cp -r 源文件夹 目标文件夹,复制文件夹cp -r -v 源文件夹 目标文件夹,复制文件夹(显示详细信息,一般用于文件夹很大,需要查看复制进度的时候)cp /usr/share/easy-rsa/2.0/keys/{ca.crt,server.{crt,key},dh2048.pem,ta.key} /etc/openvpn/keys/,复制同目录下花括号中的文件
tar cpf - . | tar xpf - -C /opt,复制当前所有文件到 /opt 目录下,一般如果文件夹文件多的情况下用这个更好,用 cp 比较容易出问题mv 文件 目标文件夹,移动文件到目标文件夹mv 文件,不指定目录重命名后的名字,用来重命名文件
touch 文件名,创建一个空白文件/更新已有文件的时间(后者少用)mkdir 文件夹名,创建文件夹mkdir -p /opt/setups/nginx/conf/,创建一个名为 conf 文件夹,如果它的上级目录 nginx 没有也会跟着一起生成,如果有则跳过rmdir 文件夹名,删除文件夹(只能删除文件夹里面是没有东西的文件夹)rm 文件,删除文件rm -r 文件夹,删除文件夹rm -r -i 文件夹,在删除文件夹里的文件会提示(要的话,在提示后面输入yes)rm -r -f 文件夹,强制删除rm -r -f 文件夹1/ 文件夹2/ 文件夹3/删除多个
find,高级查找find . -name *lin*,其中 . 代表在当前目录找,-name 表示匹配文件名 / 文件夹名,*lin* 用通配符搜索含有lin的文件或是文件夹find . -iname *lin*,其中 . 代表在当前目录找,-iname 表示匹配文件名 / 文件夹名(忽略大小写差异),*lin* 用通配符搜索含有lin的文件或是文件夹find / -name *.conf,其中 / 代表根目录查找,*.conf代表搜索后缀会.conf的文件find /opt -name .oh-my-zsh,其中 /opt 代表目录名,.oh-my-zsh 代表搜索的是隐藏文件 / 文件夹名字为 oh-my-zsh 的find /opt -type f -iname .oh-my-zsh,其中 /opt 代表目录名,-type f 代表只找文件,.oh-my-zsh 代表搜索的是隐藏文件名字为 oh-my-zsh 的find /opt -type d -iname .oh-my-zsh,其中 /opt 代表目录名,-type d 代表只找目录,.oh-my-zsh 代表搜索的是隐藏文件夹名字为 oh-my-zsh 的find . -name "lin*" -exec ls -l {} \;,当前目录搜索lin开头的文件,然后用其搜索后的结果集,再执行ls -l的命令(这个命令可变,其他命令也可以),其中 -exec 和 {} ; 都是固定格式find /opt -type f -size +800M -print0 | xargs -0 du -h | sort -nr,找出 /opt 目录下大于 800 M 的文件find / -name "*tower*" -exec rm {} \;,找到文件并删除find / -name "*tower*" -exec mv {} /opt \;,找到文件并移到 opt 目录find . -name "*" |xargs grep "youmeek",递归查找当前文件夹下所有文件内容中包含 youmeek 的文件find . -size 0 | xargs rm -f &,删除当前目录下文件大小为0的文件du -hm --max-depth=2 | sort -nr | head -12,找出系统中占用容量最大的前 12 个目录
cat /etc/resolv.conf,查看 DNS 设置netstat -tlunp,查看当前运行的服务,同时可以查看到:运行的程序已使用端口情况env,查看所有系统变量export,查看所有系统变量echoecho $JAVA_HOME,查看指定系统变量的值,这里查看的是自己配置的 JAVA_HOME。echo "字符串内容",输出 "字符串内容"echo > aa.txt,清空 aa.txt 文件内容(类似的还有:: > aa.txt,其中 : 是一个占位符, 不产生任何输出)
unset $JAVA_HOME,删除指定的环境变量ln -s /opt/data /opt/logs/data,表示给 /opt/logs 目录下创建一个名为 data 的软链接,该软链接指向到 /opt/datagrepshell grep -H '安装' *.sh,查找当前目录下所有 sh 类型文件中,文件内容包含安装的当前行内容grep 'test' java*,显示当前目录下所有以 java 开头的文件中包含 test 的行grep 'test' spring.ini docker.sh,显示当前目录下 spring.ini docker.sh 两个文件中匹配 test 的行
psps –ef|grep java,查看当前系统中有关 java 的所有进程ps -ef|grep --color java,高亮显示当前系统中有关 java 的所有进程
killkill 1234,结束 pid 为 1234 的进程kill -9 1234,强制结束 pid 为 1234 的进程(慎重)killall java,结束同一进程组内的所有为 java 进程ps -ef|grep hadoop|grep -v grep|cut -c 9-15|xargs kill -9,结束包含关键字 hadoop 的所有进程
headhead -n 10 spring.ini,查看当前文件的前 10 行内容
tailtail -n 10 spring.ini,查看当前文件的后 10 行内容tail -200f 文件名,查看文件被更新的新内容尾 200
CentOS 7 安装
概括
- 本教程中主要演示了 VMware Workstation 下安装
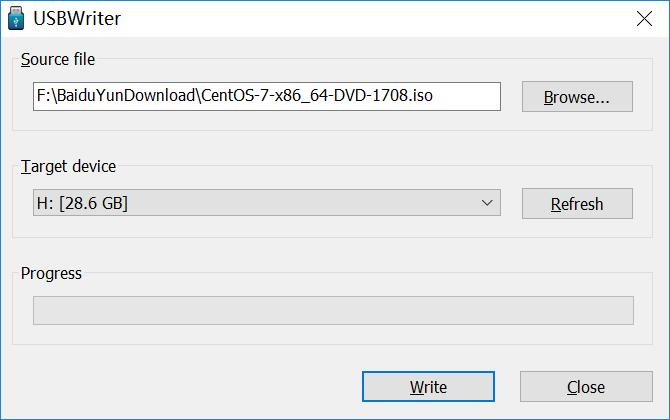
CentOS 7.3的过程。 - 如果你是要安装到 PC 机中,你需要准备一个 U 盘,以及下载这个软件:USBWriter(提取码:5aa2)
- USBWriter 的使用很简单,如下图即可制作一个 CentOS 系统盘
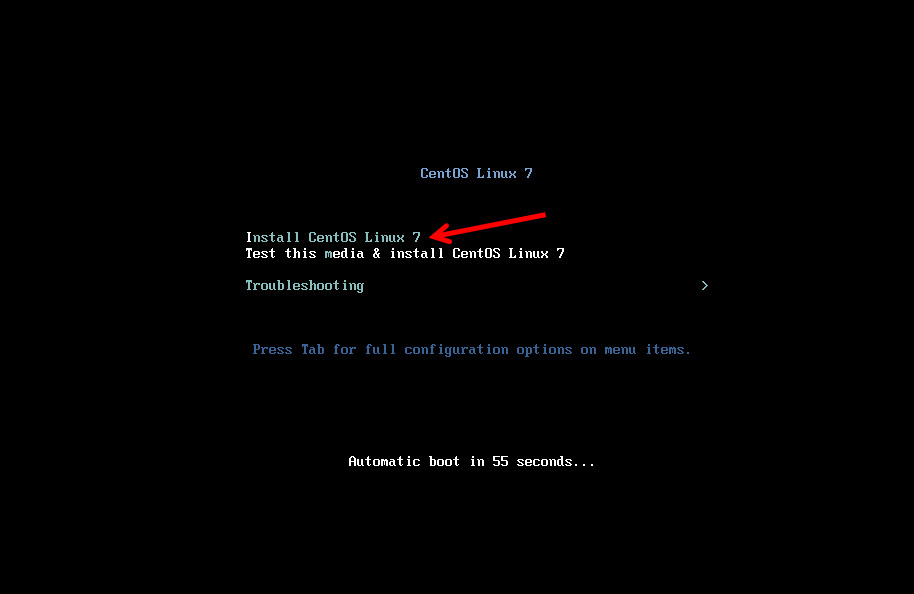
VMware 下安装 CentOS 过程
-
VMware Workstation 的介绍和下载
-
百度云下载(64 位):http://pan.baidu.com/s/1eRuJAFK
-
官网下载:http://www.vmware.com/products/workstation/workstation-evaluation
-
安装细节开始:


- 如上图,默认是最小安装,点击进去,选择桌面安装。
- 如上图,默认是自动分区,如果懂得分区,点击进去,进行手动分区,CentOS 7 少了主分区,逻辑分区的选择了。
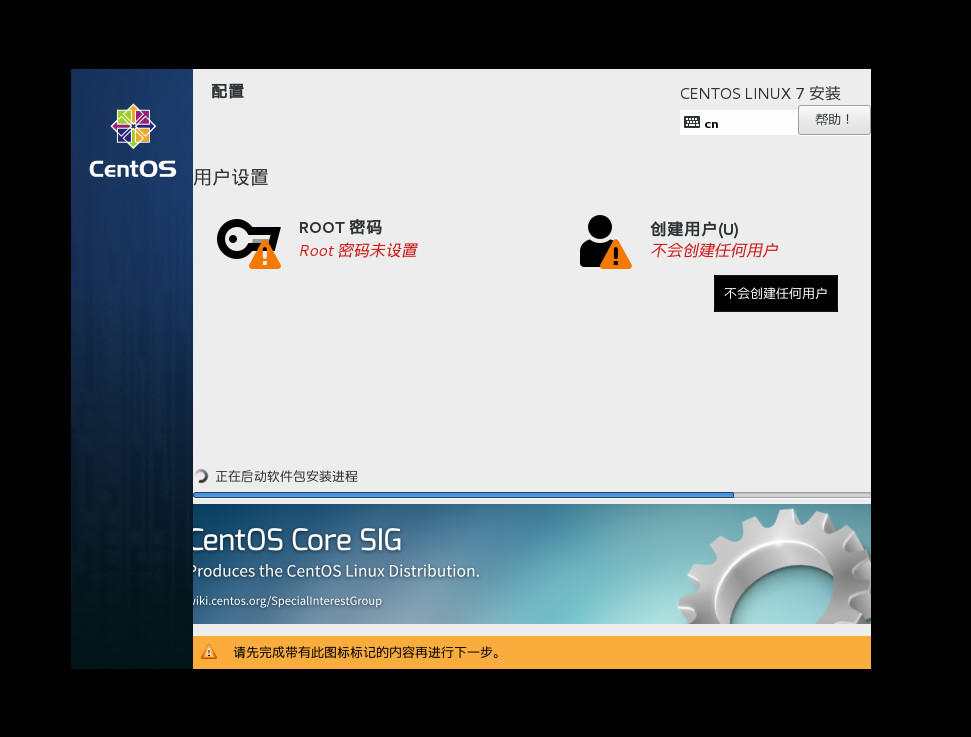
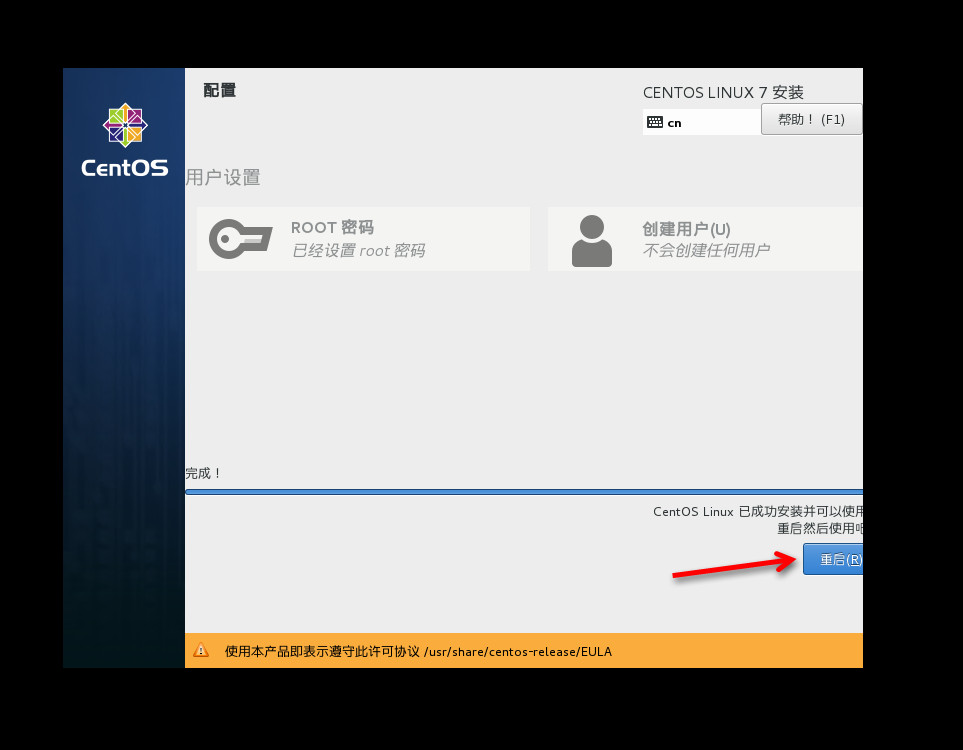
- 如上图,root 密码必须设置,我习惯测试的时候是:123456
- 我没有创建用户,喜欢用 root
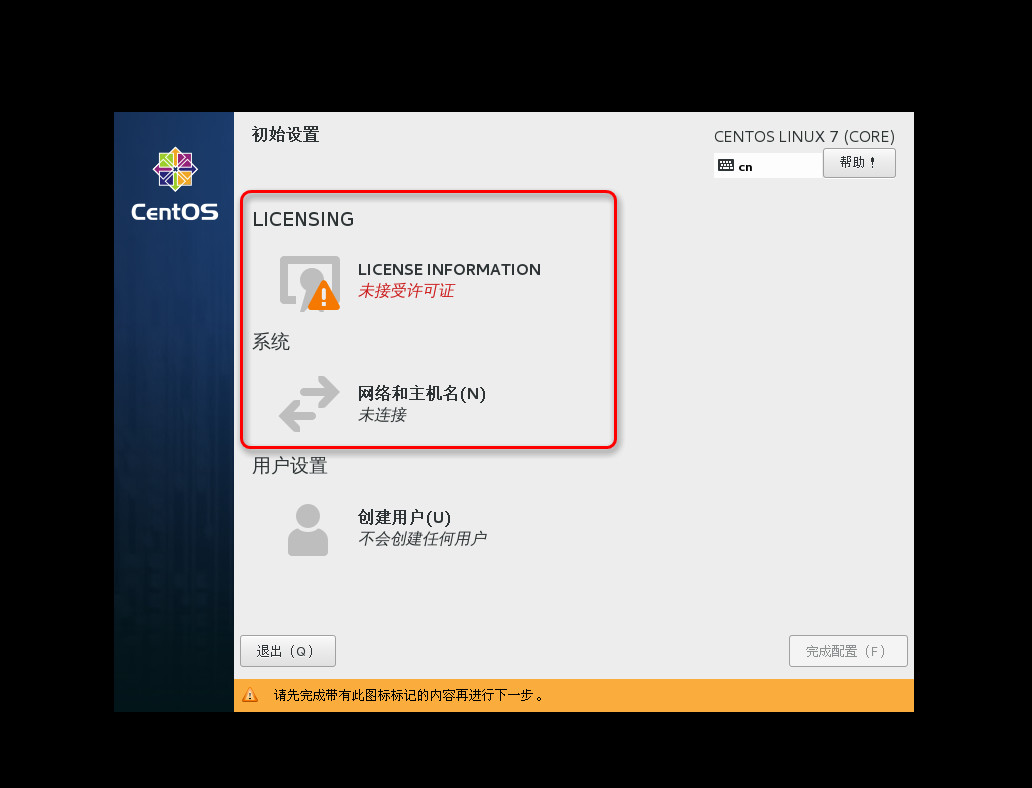
- 如上图,许可证必须点击进去勾选同意相关协议。
- 如上图,网络可以稍后在设置,主机名可以现在先填写

- 如上图右上角,一般我们都选择跳过

- 到此完成,其他该做啥就做啥
Bash 其他常用命令
其他常用命令
- 编辑 hosts 文件:
vim /etc/hosts,添加内容格式:127.0.0.1 www.youmeek.com - RPM 文件操作命令:
- 安装
rpm -i example.rpm,安装 example.rpm 包rpm -iv example.rpm,安装 example.rpm 包并在安装过程中显示正在安装的文件信息rpm -ivh example.rpm,安装 example.rpm 包并在安装过程中显示正在安装的文件信息及安装进度
- 查询
rpm -qa | grep jdk,查看 jdk 是否被安装rpm -ql jdk,查看 jdk 是否被安装
- 卸载
rpm -e jdk,卸载 jdk(一般卸载的时候都要先用 rpm -qa 看下整个软件的全名)
- 安装
- YUM 软件管理:
yum install -y httpd,安装 apacheyum remove -y httpd,卸载 apacheyum info -y httpd,查看 apache 版本信息yum list --showduplicates httpd,查看可以安装的版本yum install httpd-查询到的版本号,安装指定版本- 更多命令可以看:http://man.linuxde.net/yum
- 查看某个配置文件,排除掉里面以 # 开头的注释内容:
grep '^[^#]' /etc/openvpn/server.conf
- 查看某个配置文件,排除掉里面以 # 开头和 ; 开头的注释内容:
grep '^[^#;]' /etc/openvpn/server.conf
资料
Linux 介绍
Linux 这个名字
Linux 的 Wiki 介绍:http://zh.wikipedia.org/zh/Linux
Linux 也称:GNU/Linux,而其中 GNU 的全称又是:Gnu’s Not Unix。
其中 GNU 放前面是有原因的,GNU 介绍:http://zh.wikipedia.org/wiki/GNU
对于 Linux 和 GNU/Linux 的两种叫法是有争议,可以看下面文章:https://zh.wikipedia.org/wiki/GNU/Linux命名爭議
其实我们可以认为:Linux 本质是指 Linux 内核,而称 GNU/Linux 则代表这是一个系统,所以我认为 Debian 的这个叫法是合理的,但是确实有点不好念和记忆。所以普遍大家直接称作 Linux。
通过上面的全称和资料其实我们也就了解到,Linux 本质来源不是 Unix,但是它借鉴了 Unix 的设计思想,所以在系统业界上把这种和 Unix 是一致设计思想的系统归为:类 Unix 系统。
类 Unix 系统的介绍:https://zh.wikipedia.org/wiki/类Unix系统
类 Unix 系统,除了我们今天要讲的 Linux,还有大家熟知的 Mac OS X、FreeBSD(这两个是直接从 Unix 系发展过来的,所以相对 Linux 是比较地道的类 Unix 系统)
- FreeBSD 介绍:http://zh.wikipedia.org/zh/FreeBSD
- Mac OS X 介绍:http://zh.wikipedia.org/wiki/OS_X
Linux 的发行版本
Linux 的 Wiki 中有这句话:
通常情况下,Linux 被打包成供个人计算机和服务器使用的 Linux 发行版,一些流行的主流 Linux 发布版,包括 Debian(及其派生版本 Ubuntu、Linux Mint)、Fedora(及其相关版本 Red Hat Enterprise Linux、CentOS)和 openSUSE、ArchLinux(这个是我补充的)等。
通过上面这句话我做了总结,我个人觉得应该这样分:
- Fedora、RHEL、Centos 是一个系,他们的区别:http://blog.csdn.net/tianlesoftware/article/details/5420569
- Debian、Ubuntu 是一个系的,他们的区别直接看 Ubuntu 的 Wiki 就可以得知:http://zh.wikipedia.org/zh/Ubuntu
- ArchLinux 自己一个系:http://zh.wikipedia.org/wiki/Arch_Linux
- openSUSE 自己一个系:http://zh.wikipedia.org/wiki/OpenSUSE
根据用途可以再总结:
- Fedora 系业界一般用于做服务器
- Debian 系业界一般用于桌面,移动端,TV这一类
- ArchLinux 系,很轻量的Linux,适合有一定Linux基础,并且爱折腾的人使用,用它做桌面或是服务器都行。
- OpenSuse 系,嘛,嗯…人气相对比较差,一般是服务器。
其实 Linux 的发行版本有太多了,我也只是简单说下常见的而已,具体可以看:http://zh.wikipedia.org/wiki/Linux发行版列表
Linux 作用
为什么要用 Linux 系统?大家常看到的说法是这样的:
Linux 是一个开源的,有潜力,安全,免费的操作系统
我觉得这几个点都比较虚, 特别是免费这东西,在景德镇应该算是最不值钱的东西。作为系统的上层使用者来讲,我们之所以喜欢某个操作系统就是因为它可以加快的你生产效率,提高产能。我推荐 Linux 也只是因为它适合常见的编程语言做开发环境,仅此一点。
所有,对此我的总结就是:
如果你是某种语言的开发者,你从事这个行业,不管你怎么学习下去,Linux 永远绕不开。从简单的各种语言开发,到后期的服务器部署,分布式,集群环境,数据库相关等,Linux 都在等着你。如果你是新手程序员可能还不太懂我这句话,但是我这里可以这样提示:你可以认真去看下各个语言的官网、对应的开发组件官网,看下他们的下载和新手上路相关页面,都会有 Linux 系统对应的介绍,但是不一定有会 Windows。(P.S:微软系、美工等设计系是唯一这个总结之外的人)
在认识 Linux 作用上我以下面这边文章为结尾。Linux 和 Mac OS X 都是类 Unix 系统,所以这篇文章中基本上的理由都可以用到 Linux 上的。 为什么国外程序员爱用 Mac?http://www.vpsee.com/2009/06/why-programmers-love-mac/
推荐的发行版本
Ubuntu:适用于开发机
推荐版本:Ubuntu kylin 15.10
- Ubuntu kylin 官网:http://cn.Ubuntu.com/desktop
- Ubuntu 英文官网:http://www.ubuntu.com
- Ubuntu 中文官网:http://www.ubuntu.org.cn
- 网易镜像:http://mirrors.163.com/ubuntu-releases/
- 阿里云镜像:http://mirrors.aliyun.com/ubuntu-releases/
- Ubuntu kylin 15.10 64 位镜像地址:http://cdimage.ubuntu.com/ubuntukylin/releases/15.10/release/ubuntukylin-15.10-desktop-amd64.iso
推荐理由:
我们是要在上面做开发的,不是要把他变成生活用机的,所以你认为自己尝试安装各种中文输入法很爽吗?自己尝试让国际 Ubuntu 版变成又一个符合国情的 kylin 很爽吗?真心别折腾这些没用的东西。就像我以前说的,大学老师让 Java 新手使用记事本写代码就是一种非常 shit 行为,不断地在 Windows 上用 cmd > javac 是毫无意义的。
CentOS:适用于服务器机
推荐版本:6.7
- CentOS 官网:http://www.centos.org/download/
- 网易镜像:http://mirrors.163.com/centos/
- 阿里云镜像:http://mirrors.aliyun.com/centos/
- CentOS 6.7 64 位镜像地址:http://mirrors.163.com/centos/6.7/isos/x86_64/CentOS-6.7-x86_64-bin-DVD1.iso
推荐理由:
Fedora(CentOS、RHEL) 系,是在国内外,作为企业服务器的系统最多,没有之一。我在 Quora 和知乎上也搜索了下,基本上大家都是赞同这个观点的。
Linux 应用
Linux 主要作为Linux发行版(通常被称为"distro")的一部分而使用。这些发行版由个人,松散组织的团队,以及商业机构和志愿者组织编写。它们通常包括了其他的系统软件和应用软件,以及一个用来简化系统初始安装的安装工具,和让软件安装升级的集成管理器。大多数系统还包括了像提供GUI界面的XFree86之类的曾经运行于BSD的程序。 一个典型的Linux发行版包括:Linux内核,一些GNU程序库和工具,命令行shell,图形界面的X Window系统和相应的桌面环境,如KDE或GNOME,并包含数千种从办公套件,编译器,文本编辑器到科学工具的应用软件。
Zookeeper 安装
Docker 部署 Zookeeper
单个实例
- 官网仓库:https://hub.docker.com/r/library/zookeeper/
- 单个实例:
docker run -d --restart always --name one-zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime zookeeper:latest- 默认端口暴露是:
This image includes EXPOSE 2181 2888 3888 (the zookeeper client port, follower port, election port respectively)
- 默认端口暴露是:
- 容器中的几个重要目录(有需要挂载的可以指定):
/data/datalog/conf
单机多个实例(集群)
- 创建 docker compose 文件:
vim zookeeper.yml - 下面内容来自官网仓库:https://hub.docker.com/r/library/zookeeper/
version: '3.1'
services:
zoo1:
image: zookeeper
restart: always
hostname: zoo1
ports:
- 2181:2181
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=0.0.0.0:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888
zoo2:
image: zookeeper
restart: always
hostname: zoo2
ports:
- 2182:2181
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=0.0.0.0:2888:3888 server.3=zoo3:2888:3888
zoo3:
image: zookeeper
restart: always
hostname: zoo3
ports:
- 2183:2181
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=0.0.0.0:2888:3888
- 启动:
docker-compose -f zookeeper.yml -p zk_test up -d- 参数 -p zk_test 表示这个 compose project 的名字,等价于:
COMPOSE_PROJECT_NAME=zk_test docker-compose -f zookeeper.yml up -d - 不指定项目名称,Docker-Compose 默认以当前文件目录名作为应用的项目名
- 报错是正常情况的。
- 参数 -p zk_test 表示这个 compose project 的名字,等价于:
- 停止:
docker-compose -f zookeeper.yml -p zk_test stop
先安装 nc 再来校验 zookeeper 集群情况
- 环境:CentOS 7.4
- 官网下载:https://nmap.org/download.html,找到 rpm 包
- 当前时间(201803)最新版本下载:
wget https://nmap.org/dist/ncat-7.60-1.x86_64.rpm - 安装:
sudo rpm -i ncat-7.60-1.x86_64.rpm - ln 下:
sudo ln -s /usr/bin/ncat /usr/bin/nc - 检验:
nc --version
校验
- 命令:
echo stat | nc 127.0.0.1 2181,得到如下信息:
Zookeeper version: 3.4.11-37e277162d567b55a07d1755f0b31c32e93c01a0, built on 11/01/2017 18:06 GMT
Clients:
/172.21.0.1:58872[0](queued=0,recved=1,sent=0)
Latency min/avg/max: 0/0/0
Received: 1
Sent: 0
Connections: 1
Outstanding: 0
Zxid: 0x100000000
Mode: follower
Node count: 4
- 命令:
echo stat | nc 127.0.0.1 2182,得到如下信息:
Zookeeper version: 3.4.11-37e277162d567b55a07d1755f0b31c32e93c01a0, built on 11/01/2017 18:06 GMT
Clients:
/172.21.0.1:36190[0](queued=0,recved=1,sent=0)
Latency min/avg/max: 0/0/0
Received: 1
Sent: 0
Connections: 1
Outstanding: 0
Zxid: 0x500000000
Mode: follower
Node count: 4
- 命令:
echo stat | nc 127.0.0.1 2183,得到如下信息:
Zookeeper version: 3.4.11-37e277162d567b55a07d1755f0b31c32e93c01a0, built on 11/01/2017 18:06 GMT
Clients:
/172.21.0.1:33344[0](queued=0,recved=1,sent=0)
Latency min/avg/max: 0/0/0
Received: 1
Sent: 0
Connections: 1
Outstanding: 0
Zxid: 0x500000000
Mode: leader
Node count: 4
多机多个实例(集群)
- 三台机子:
- 内网 ip:
172.24.165.129,外网 ip:47.91.22.116 - 内网 ip:
172.24.165.130,外网 ip:47.91.22.124 - 内网 ip:
172.24.165.131,外网 ip:47.74.6.138
- 内网 ip:
- 修改三台机子 hostname:
- 节点 1:
hostnamectl --static set-hostname youmeekhost1 - 节点 2:
hostnamectl --static set-hostname youmeekhost2 - 节点 3:
hostnamectl --static set-hostname youmeekhost3
- 节点 1:
- 三台机子的 hosts 都修改为如下内容:
vim /etc/hosts
172.24.165.129 youmeekhost1
172.24.165.130 youmeekhost2
172.24.165.131 youmeekhost3
- 节点 1:
docker run -d \
-v /data/docker/zookeeper/data:/data \
-v /data/docker/zookeeper/log:/datalog \
-e ZOO_MY_ID=1 \
-e "ZOO_SERVERS=server.1=youmeekhost1:2888:3888 server.2=youmeekhost2:2888:3888 server.3=youmeekhost3:2888:3888" \
--name=zookeeper1 --net=host --restart=always zookeeper
- 节点 2:
docker run -d \
-v /data/docker/zookeeper/data:/data \
-v /data/docker/zookeeper/log:/datalog \
-e ZOO_MY_ID=2 \
-e "ZOO_SERVERS=server.1=youmeekhost1:2888:3888 server.2=youmeekhost2:2888:3888 server.3=youmeekhost3:2888:3888" \
--name=zookeeper2 --net=host --restart=always zookeeper
- 节点 3:
docker run -d \
-v /data/docker/zookeeper/data:/data \
-v /data/docker/zookeeper/log:/datalog \
-e ZOO_MY_ID=3 \
-e "ZOO_SERVERS=server.1=youmeekhost1:2888:3888 server.2=youmeekhost2:2888:3888 server.3=youmeekhost3:2888:3888" \
--name=zookeeper3 --net=host --restart=always zookeeper
需要环境
- JDK 安装
下载安装
- 官网:https://zookeeper.apache.org/
- 此时(201702)最新稳定版本:Release
3.4.9 - 官网下载:http://www.apache.org/dyn/closer.cgi/zookeeper/
- 我这里以:
zookeeper-3.4.8.tar.gz为例 - 安装过程:
mkdir -p /usr/program/zookeeper/datacd /opt/setupstar zxvf zookeeper-3.4.8.tar.gzmv /opt/setups/zookeeper-3.4.8 /usr/program/zookeepercd /usr/program/zookeeper/zookeeper-3.4.8/confmv zoo_sample.cfg zoo.cfgvim zoo.cfg
- 将配置文件中的这个值:
- 原值:
dataDir=/tmp/zookeeper - 改为:
dataDir=/usr/program/zookeeper/data
- 原值:
- 防火墙开放2181端口
iptables -A INPUT -p tcp -m tcp --dport 2181 -j ACCEPTservice iptables saveservice iptables restart
- 启动 zookeeper:
sh /usr/program/zookeeper/zookeeper-3.4.8/bin/zkServer.sh start - 停止 zookeeper:
sh /usr/program/zookeeper/zookeeper-3.4.8/bin/zkServer.sh stop - 查看 zookeeper 状态:
sh /usr/program/zookeeper/zookeeper-3.4.8/bin/zkServer.sh status- 如果是集群环境,下面几种角色
- leader
- follower
- 如果是集群环境,下面几种角色
集群环境搭建
确定机子环境
- 集群环境最少节点是:3,且节点数必须是奇数,生产环境推荐是:5 个机子节点。
- 系统都是 CentOS 6
- 机子 1:192.168.1.121
- 机子 2:192.168.1.111
- 机子 3:192.168.1.112
配置
- 在三台机子上都做如上文的流程安装,再补充修改配置文件:
vim /usr/program/zookeeper/zookeeper-3.4.8/conf/zoo.cfg - 三台机子都增加下面内容:
server.1=192.168.1.121:2888:3888
server.2=192.168.1.111:2888:3888
server.3=192.168.1.112:2888:3888
- 在 机子 1 增加一个该文件:
vim /usr/program/zookeeper/data/myid,文件内容填写:1 - 在 机子 2 增加一个该文件:
vim /usr/program/zookeeper/data/myid,文件内容填写:2 - 在 机子 3 增加一个该文件:
vim /usr/program/zookeeper/data/myid,文件内容填写:3 - 然后在三台机子上都启动 zookeeper:
sh /usr/program/zookeeper/zookeeper-3.4.8/bin/zkServer.sh start - 分别查看三台机子的状态:
sh /usr/program/zookeeper/zookeeper-3.4.8/bin/zkServer.sh status,应该会得到类似这样的结果:
Using config: /usr/program/zookeeper/zookeeper-3.4.8/bin/../conf/zoo.cfg
Mode: follower 或者 Mode: leader
Zookeeper 客户端工具
ZooInspector
- 下载地址:https://issues.apache.org/jira/secure/attachment/12436620/ZooInspector.zip
- 解压,双击 jar 文件,效果如下:
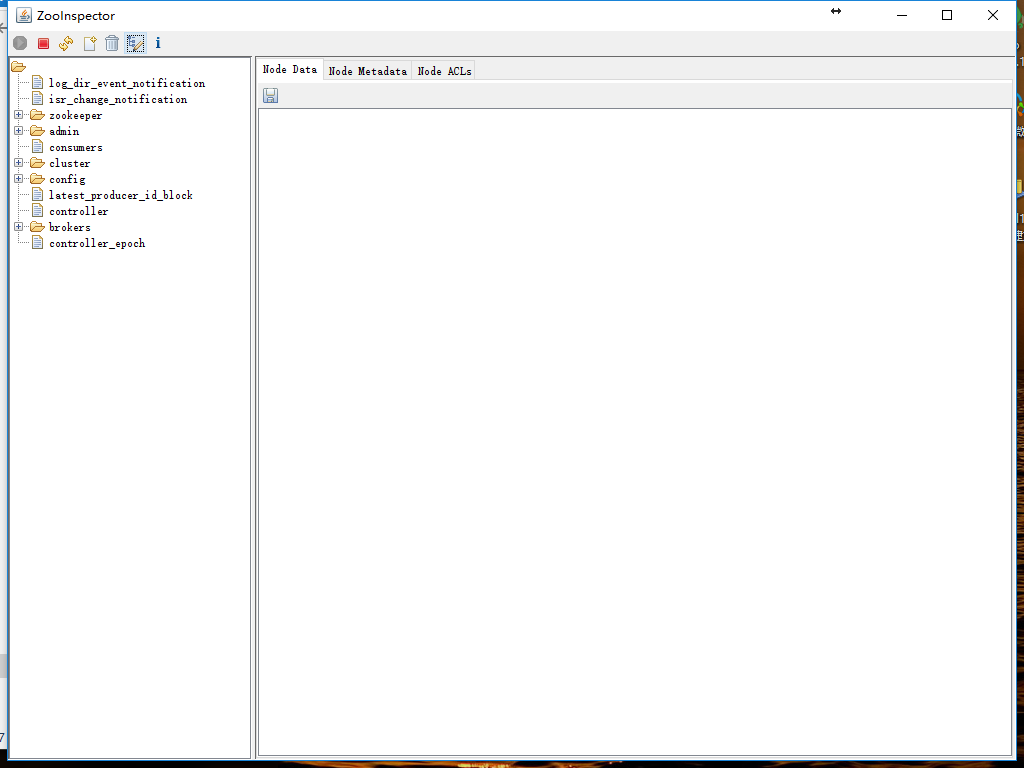

zooweb
- 下载地址:https://github.com/zhuhongyu345/zooweb
- Spring Boot 的 Web 项目,直接:
java -jar zooweb-1.0.jar启动 web 服务,然后访问:http://127.0.0.1:9345 
资料
FTP(File Transfer Protocol)介绍
FTP 安装
-
查看是否已安装:
-
CentOS:
rpm -qa | grep vsftpd -
Ubuntu:
dpkg -l | grep vsftpd -
安装:
-
CentOS 6:
sudo yum install -y vsftpd -
Ubuntu:
sudo apt-get install -y vsftpd
FTP 使用之前要点
- 关闭 CentOS 上的 SELinux 组件(Ubuntu 体系是没有这东西的)。
- 查看 SELinux 开启状态:
sudo getenforce- 有如下三种状态,默认是 Enforcing
- Enforcing(开启)
- Permissive(开启,但是只起到警告作用,属于比较轻的开启)
- Disabled(关闭)
- 临时关闭:
- 命令:
sudo setenforce 0
- 命令:
- 临时开启:
- 命令:
sudo setenforce 1
- 命令:
- 永久关闭:
- 命令:
sudo vim /etc/selinux/config - 将:
SELINUX=enforcing改为SELINUX=disbaled,配置好之后需要重启系统。
- 命令:
- 有如下三种状态,默认是 Enforcing
FTP 服务器配置文件常用参数
- vsftpd 默认是支持使用 Linux 系统里的账号进行登录的(登录上去可以看到自己的 home 目录内容),权限跟 Linux 的账号权限一样。但是建议使用软件提供的虚拟账号管理体系功能,用虚拟账号登录。
- 配置文件介绍(记得先备份):
sudo vim /etc/vsftpd/vsftpd.conf,比较旧的系统版本是:vim /etc/vsftpd.conf - 该配置主要参数解释:
- anonymous_enable=NO #不允许匿名访问,改为YES即表示可以匿名登录
- anon_upload_enable=YES #是否允许匿名用户上传
- anon_mkdir_write_enable=YES #是否允许匿名用户创建目录
- local_enable=YES #是否允许本地用户,也就是linux系统的已有账号,如果你要FTP的虚拟账号,那可以改为NO
- write_enable=YES #是否允许本地用户具有写权限
- local_umask=022 #本地用户掩码
- chroot_list_enable=YES #不锁定用户在自己的家目录,默认是注释,建议这个一定要开,比如本地用户judasn,我们只能看到/home/judasn,没办法看到/home目录
- chroot_list_file=/etc/vsftpd/chroot_list #该选项是配合上面选项使用的。此文件中的用户将启用 chroot,如果上面的功能开启是不够的还要把用户名加到这个文件里面。配置好后,登录的用户,默认登录上去看到的根目录就是自己的home目录。
- listen=YES #独立模式
- userlist_enable=YES #用户访问控制,如果是YES,则表示启用vsftp的虚拟账号功能,虚拟账号配置文件是/etc/vsftpd/user_list
- userlist_deny=NO #这个属性在配置文件是没有的,当userlist_enable=YES,这个值也为YES,则user_list文件中的用户不能登录FTP,列表外的用户可以登录,也可以起到一个黑名单的作用。当userlist_enable=YES,这个值为NO,则user_list文件中的用户能登录FTP,列表外的用户不可以登录,也可以起到一个白名单的作用。如果同一个用户即在白名单中又在ftpusers黑名单文件中,那还是会以黑名单为前提,对应账号没法登录。
- tcp_wrappers=YES #是否启用TCPWrappers管理服务
- FTP用户黑名单配置文件:
sudo vim /etc/vsftpd/ftpusers,默认root用户也在黑名单中 - 控制FTP用户登录配置文件:
sudo vim /etc/vsftpd/user_list - 启动服务:
service vsftpd restart
vsftpd 的两种传输模式
- 分为:主动模式(PORT)和被动模式(PASV)。这两个模式会涉及到一些端口问题,也就涉及到防火墙问题,所以要特别注意。主动模式比较简单,只要在防火墙上放开放开 21 和 20 端口即可。被动模式则要根据情况放开一个端口段。
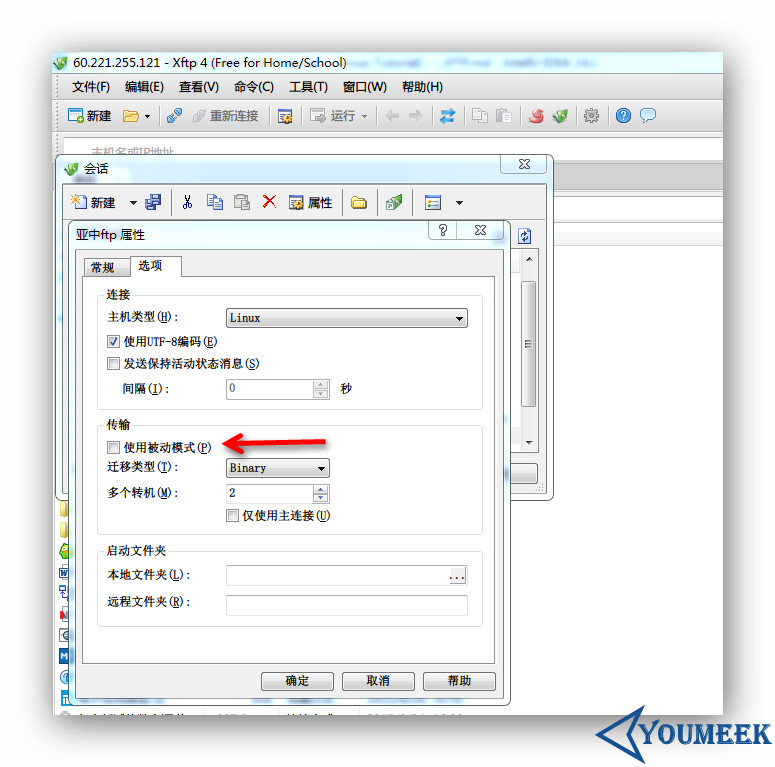
- 上图箭头:xftp 新建连接默认都是勾选被动模式的,所以如果要使用主动模式,在该连接的属性中是要去掉勾选。
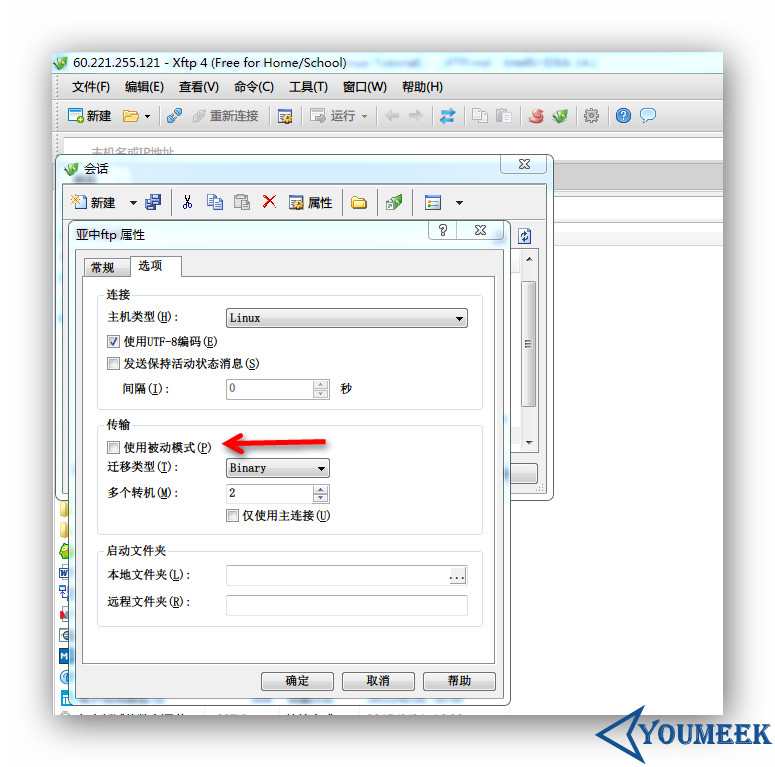
vsftpd 的两种运行模式
- 分为:xinetd 模式和 standalone 模式
- xinetd 模式:由 xinetd 作为 FTP 的守护进程,负责 21 端口的监听,一旦外部发起对 21 端口的连接,则调用 FTP 的主程序处理,连接完成后,则关闭 FTP 主程序,释放内存资源。好处是资源占用少,适合 FTP 连接数较少的场合。
- standalone 模式:直接使用 FTP 主程序作为 FTP 的守护进程,负责 21 端口的监听,由于无需经过 xinetd 的前端代理,响应速度快,适合连接数 较大的情况,但由于 FTP 主程序长期驻留内存,故较耗资源。
- standalone 一次性启动,运行期间一直驻留在内存中,优点是对接入信号反应快,缺点是损耗了一定的系统资源,因此经常应用于对实时反应要求较高的 专业 FTP 服务器。
- xinetd 恰恰相反,由于只在外部连接发送请求时才调用 FTP 进程,因此不适合应用在同时连接数量较多的系统。此外,xinetd 模式不占用系统资源。除了反应速度和占用资源两方面的影响外,vsftpd 还提供了一些额外的高级功能,如 xinetd 模式支持 per_IP (单一 IP)限制,而 standalone 模式则更有利于 PAM 验证功能的应用。
- 配置 xinetd 模式:
- 编辑配置文件:
sudo vim /etc/xinetd.d/vsftpd - 属性信息改为如下信息:
- disable = no
- socket_type = stream
- wait = no #这表示设备是激活的,它正在使用标准的TCP Sockets
- 编辑配置文件:
sudo vim /etc/vsftpd/vsftpd.conf - 如果该配置选项中的有
listen=YES,则要注释掉
- 编辑配置文件:
- 重启 xinetd 服务,命令:
sudo /etc/rc.d/init.d/xinetd restart - 配置 standalone 模式:
- 编辑配置文件:
sudo vim /etc/xinetd.d/vsftpd - 属性信息改为如下信息:
- disable = yes
- 编辑配置文件:
sudo vim /etc/vsftpd/vsftpd.conf - 属性信息改为如下信息:
- Listen=YES(如果是注释掉则要打开注释)
- 编辑配置文件:
- 重启服务:
sudo service vsftpd restart
- 配置 xinetd 模式:
FTP 资料
- http://www.jikexueyuan.com/course/994.html
- http://www.while0.com/36.html
- http://www.cnblogs.com/CSGrandeur/p/3754126.html
- http://www.centoscn.com/image-text/config/2015/0613/5651.html
- http://wiki.ubuntu.org.cn/Vsftpd
CI 一整套服务
环境说明
- CentOS 7.7
- 两台机子(一台机子也是可以,内存至少要 8G)
- 一台:Gitlab + Redis + Postgresql
- 硬件推荐:内存 4G
- 端口安排
- Gitlab:10080
- 一台:Nexus + Jenkins + SonarQube + Postgresql
- 硬件推荐:内存 8G
- 端口安排
- SonarQube:19000
- Nexus:18081
- Jenkins:18080
- 一台:Gitlab + Redis + Postgresql
Gitlab + Redis + Postgresql
- 预计会使用内存:2G 左右
- 这套方案来自(部分内容根据自己情况进行了修改):https://github.com/sameersbn/docker-gitlab
- 创建宿主机挂载目录:
mkdir -p /data/docker/gitlab/gitlab /data/docker/gitlab/redis /data/docker/gitlab/postgresql - 赋权(避免挂载的时候,一些程序需要容器中的用户的特定权限使用):
chmod -R 777 /data/docker/gitlab/gitlab /data/docker/gitlab/redis /data/docker/gitlab/postgresql - 这里使用 docker-compose 的启动方式,所以需要创建 docker-compose.yml 文件:
version: '2'
services:
redis:
restart: always
image: sameersbn/redis:latest
command:
- --loglevel warning
volumes:
- /data/docker/gitlab/redis:/var/lib/redis:Z
postgresql:
restart: always
image: sameersbn/postgresql:9.6-2
volumes:
- /data/docker/gitlab/postgresql:/var/lib/postgresql:Z
environment:
- DB_USER=gitlab
- DB_PASS=password
- DB_NAME=gitlabhq_production
- DB_EXTENSION=pg_trgm
gitlab:
restart: always
image: sameersbn/gitlab:10.4.2-1
depends_on:
- redis
- postgresql
ports:
- "10080:80"
- "10022:22"
volumes:
- /data/docker/gitlab/gitlab:/home/git/data:Z
environment:
- DEBUG=false
- DB_ADAPTER=postgresql
- DB_HOST=postgresql
- DB_PORT=5432
- DB_USER=gitlab
- DB_PASS=password
- DB_NAME=gitlabhq_production
- REDIS_HOST=redis
- REDIS_PORT=6379
- TZ=Asia/Shanghai
- GITLAB_TIMEZONE=Beijing
- GITLAB_HTTPS=false
- SSL_SELF_SIGNED=false
- GITLAB_HOST=192.168.0.105
- GITLAB_PORT=10080
- GITLAB_SSH_PORT=10022
- GITLAB_RELATIVE_URL_ROOT=
- GITLAB_SECRETS_DB_KEY_BASE=long-and-random-alphanumeric-string
- GITLAB_SECRETS_SECRET_KEY_BASE=long-and-random-alphanumeric-string
- GITLAB_SECRETS_OTP_KEY_BASE=long-and-random-alphanumeric-string
- GITLAB_ROOT_PASSWORD=
- GITLAB_ROOT_EMAIL=
- GITLAB_NOTIFY_ON_BROKEN_BUILDS=true
- GITLAB_NOTIFY_PUSHER=false
- GITLAB_EMAIL=notifications@example.com
- GITLAB_EMAIL_REPLY_TO=noreply@example.com
- GITLAB_INCOMING_EMAIL_ADDRESS=reply@example.com
- GITLAB_BACKUP_SCHEDULE=daily
- GITLAB_BACKUP_TIME=01:00
- SMTP_ENABLED=false
- SMTP_DOMAIN=www.example.com
- SMTP_HOST=smtp.gmail.com
- SMTP_PORT=587
- SMTP_USER=mailer@example.com
- SMTP_PASS=password
- SMTP_STARTTLS=true
- SMTP_AUTHENTICATION=login
- IMAP_ENABLED=false
- IMAP_HOST=imap.gmail.com
- IMAP_PORT=993
- IMAP_USER=mailer@example.com
- IMAP_PASS=password
- IMAP_SSL=true
- IMAP_STARTTLS=false
- OAUTH_ENABLED=false
- OAUTH_AUTO_SIGN_IN_WITH_PROVIDER=
- OAUTH_ALLOW_SSO=
- OAUTH_BLOCK_AUTO_CREATED_USERS=true
- OAUTH_AUTO_LINK_LDAP_USER=false
- OAUTH_AUTO_LINK_SAML_USER=false
- OAUTH_EXTERNAL_PROVIDERS=
- OAUTH_CAS3_LABEL=cas3
- OAUTH_CAS3_SERVER=
- OAUTH_CAS3_DISABLE_SSL_VERIFICATION=false
- OAUTH_CAS3_LOGIN_URL=/cas/login
- OAUTH_CAS3_VALIDATE_URL=/cas/p3/serviceValidate
- OAUTH_CAS3_LOGOUT_URL=/cas/logout
- OAUTH_GOOGLE_API_KEY=
- OAUTH_GOOGLE_APP_SECRET=
- OAUTH_GOOGLE_RESTRICT_DOMAIN=
- OAUTH_FACEBOOK_API_KEY=
- OAUTH_FACEBOOK_APP_SECRET=
- OAUTH_TWITTER_API_KEY=
- OAUTH_TWITTER_APP_SECRET=
- OAUTH_GITHUB_API_KEY=
- OAUTH_GITHUB_APP_SECRET=
- OAUTH_GITHUB_URL=
- OAUTH_GITHUB_VERIFY_SSL=
- OAUTH_GITLAB_API_KEY=
- OAUTH_GITLAB_APP_SECRET=
- OAUTH_BITBUCKET_API_KEY=
- OAUTH_BITBUCKET_APP_SECRET=
- OAUTH_SAML_ASSERTION_CONSUMER_SERVICE_URL=
- OAUTH_SAML_IDP_CERT_FINGERPRINT=
- OAUTH_SAML_IDP_SSO_TARGET_URL=
- OAUTH_SAML_ISSUER=
- OAUTH_SAML_LABEL="Our SAML Provider"
- OAUTH_SAML_NAME_IDENTIFIER_FORMAT=urn:oasis:names:tc:SAML:2.0:nameid-format:transient
- OAUTH_SAML_GROUPS_ATTRIBUTE=
- OAUTH_SAML_EXTERNAL_GROUPS=
- OAUTH_SAML_ATTRIBUTE_STATEMENTS_EMAIL=
- OAUTH_SAML_ATTRIBUTE_STATEMENTS_NAME=
- OAUTH_SAML_ATTRIBUTE_STATEMENTS_FIRST_NAME=
- OAUTH_SAML_ATTRIBUTE_STATEMENTS_LAST_NAME=
- OAUTH_CROWD_SERVER_URL=
- OAUTH_CROWD_APP_NAME=
- OAUTH_CROWD_APP_PASSWORD=
- OAUTH_AUTH0_CLIENT_ID=
- OAUTH_AUTH0_CLIENT_SECRET=
- OAUTH_AUTH0_DOMAIN=
- OAUTH_AZURE_API_KEY=
- OAUTH_AZURE_API_SECRET=
- OAUTH_AZURE_TENANT_ID=
- 启动:
docker-compose up -d,启动比较慢,等个 2 分钟左右。 - 浏览器访问 Gitlab:http://192.168.0.105:10080/users/sign_in
- 默认用户是 root,密码首次访问必须重新设置,并且最小长度为 8 位,我习惯设置为:aa123456
- 添加 SSH key:http://192.168.0.105:10080/profile/keys
- Gitlab 的具体使用可以看另外文章:Gitlab 的使用
Nexus + Jenkins + SonarQube
- 预计会使用内存:4G 左右
- 创建宿主机挂载目录:
mkdir -p /data/docker/ci/nexus /data/docker/ci/jenkins /data/docker/ci/jenkins/lib /data/docker/ci/jenkins/home /data/docker/ci/sonarqube /data/docker/ci/postgresql /data/docker/ci/gatling/results - 赋权(避免挂载的时候,一些程序需要容器中的用户的特定权限使用):
chmod -R 777 /data/docker/ci/nexus /data/docker/ci/jenkins/lib /data/docker/ci/jenkins/home /data/docker/ci/sonarqube /data/docker/ci/postgresql /data/docker/ci/gatling/results - 下面有一个细节要特别注意:yml 里面不能有中文。还有就是 sonar 的挂载目录不能直接挂在 /opt/sonarqube 上,不然会启动不了。
- 这里使用 docker-compose 的启动方式,所以需要创建 docker-compose.yml 文件:
version: '3'
networks:
prodnetwork:
driver: bridge
services:
sonardb:
image: postgres:9.6.6
restart: always
ports:
- "5433:5432"
networks:
- prodnetwork
volumes:
- /data/docker/ci/postgresql:/var/lib/postgresql
environment:
- POSTGRES_USER=sonar
- POSTGRES_PASSWORD=sonar
sonar:
image: sonarqube:6.7.1
restart: always
ports:
- "19000:9000"
- "19092:9092"
networks:
- prodnetwork
depends_on:
- sonardb
volumes:
- /data/docker/ci/sonarqube/conf:/opt/sonarqube/conf
- /data/docker/ci/sonarqube/data:/opt/sonarqube/data
- /data/docker/ci/sonarqube/extension:/opt/sonarqube/extensions
- /data/docker/ci/sonarqube/bundled-plugins:/opt/sonarqube/lib/bundled-plugins
environment:
- SONARQUBE_JDBC_URL=jdbc:postgresql://sonardb:5432/sonar
- SONARQUBE_JDBC_USERNAME=sonar
- SONARQUBE_JDBC_PASSWORD=sonar
nexus:
image: sonatype/nexus3
restart: always
ports:
- "18081:8081"
networks:
- prodnetwork
volumes:
- /data/docker/ci/nexus:/nexus-data
jenkins:
image: wine6823/jenkins:1.1
restart: always
ports:
- "18080:8080"
networks:
- prodnetwork
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /usr/bin/docker:/usr/bin/docker
- /etc/localtime:/etc/localtime:ro
- $HOME/.ssh:/root/.ssh
- /data/docker/ci/jenkins/lib:/var/lib/jenkins/
- /data/docker/ci/jenkins/home:/var/jenkins_home
depends_on:
- nexus
- sonar
environment:
- NEXUS_PORT=8081
- SONAR_PORT=9000
- SONAR_DB_PORT=5432
- 启动:
docker-compose up -d,启动比较慢,等个 2 分钟左右。 - 浏览器访问 SonarQube:http://192.168.0.105:19000
- 默认用户名:admin
- 默认密码:admin
- 插件安装地址:http://192.168.0.105:19000/admin/marketplace
- 代码检查规范选择:http://192.168.0.105:19000/profiles
- 如果没有安装相关检查插件,默认是没有内容可以设置,建议现在插件市场安装 FindBugs,这样也可以帮你生成插件目录:
/extension/plugins - 如果你有其他额外插件,可以把 jar 放在
${SONAR_HOME}/extension/plugins目录下,然后重启下 sonar
- 如果没有安装相关检查插件,默认是没有内容可以设置,建议现在插件市场安装 FindBugs,这样也可以帮你生成插件目录:
- 浏览器访问 Nexus:http://192.168.0.105:18081
- 默认用户名:admin
- 默认密码:admin123
- 浏览器访问 Jenkins:http://192.168.0.105:18080
- 首次进入 Jenkins 的 Web UI 界面是一个解锁页面 Unlock Jenkins,需要让你输入:Administrator password
- 这个密码放在:
/var/jenkins_home/secrets/initialAdminPassword,你需要先:docker exec -it ci_jenkins_1 /bin/bash- 然后:
cat /var/jenkins_home/secrets/initialAdminPassword,找到初始化密码
- 然后:
- 这个密码放在:
- 首次进入 Jenkins 的 Web UI 界面是一个解锁页面 Unlock Jenkins,需要让你输入:Administrator password
配置 Jenkins 拉取代码权限
- 因为 dockerfile 中我已经把宿主机的 .ssh 下的挂载在 Jenkins 的容器中
- 所以读取宿主机的 pub:
cat ~/.ssh/id_rsa.pub,然后配置在 Gitlab 中:http://192.168.0.105:10080/profile/keys - Jenkinsfile 中 Git URL 使用:ssh 协议,比如:
ssh://git@192.168.0.105:10022/gitnavi/spring-boot-ci-demo.git
Jenkins 特殊配置(减少权限问题,如果是内网的话)
- 访问:http://192.168.0.105:18080/configureSecurity/
- 去掉
防止跨站点请求伪造 - 勾选
登录用户可以做任何事下面的:Allow anonymous read access
- 去掉
配置 Gitlab Webhook
- Jenkins 访问:http://192.168.0.105:18080/job/任务名/configure
- 在
Build Triggers勾选:触发远程构建 (例如,使用脚本),在身份验证令牌输入框填写任意字符串,这个等下 Gitlab 会用到,假设我这里填写:112233
- 在
- Gitlab 访问:http://192.168.0.105:10080/用户名/项目名/settings/integrations
- 在
URL中填写:http://192.168.0.105:18080/job/任务名/build?token=112233
- 在
资料
LDAP 安装和配置
LDAP 基本概念
- https://segmentfault.com/a/1190000002607140
- http://www.itdadao.com/articles/c15a1348510p0.html
- http://blog.csdn.net/reblue520/article/details/51804162
LDAP 服务器端安装
- 环境:CentOS 7.3 x64(为了方便,已经禁用了防火墙)
- 常见服务端:
- 这里选择:OpenLDAP,安装(最新的是 2.4.40):
yum install -y openldap openldap-clients openldap-servers migrationtools - 配置:
cp /usr/share/openldap-servers/DB_CONFIG.example /var/lib/ldap/DB_CONFIGchown ldap. /var/lib/ldap/DB_CONFIG
- 启动:
systemctl start slapdsystemctl enable slapd
- 查看占用端口(默认用的是 389):
netstat -tlnp | grep slapd
设置OpenLDAP管理员密码
- 输入命令:
slappasswd,重复输入两次明文密码后(我是:123456),我得到一个加密后密码(后面会用到):{SSHA}YK8qBtlmEpjUiVEPyfmNNDALjBaUTasc - 新建临时配置目录:
mkdir /root/my_ldif ; cd /root/my_ldifvim chrootpw.ldif,添加如下内容:
dn: olcDatabase={0}config,cn=config
changetype: modify
add: olcRootPW
olcRootPW: {SSHA}YK8qBtlmEpjUiVEPyfmNNDALjBaUTasc
- 添加刚刚写的配置(过程比较慢):
ldapadd -Y EXTERNAL -H ldapi:/// -f chrootpw.ldif - 导入默认的基础配置(过程比较慢):
for i in /etc/openldap/schema/*.ldif; do ldapadd -Y EXTERNAL -H ldapi:/// -f $i; done
修改默认的domain
- 输入命令:
slappasswd,重复输入两次明文密码后(我是:111111),我得到一个加密后密码(后面会用到):{SSHA}rNLkIMYKvYhbBjxLzSbjVsJnZSkrfC3w cd /root/my_ldif ; vim chdomain.ldif,添加如下内容(cn,dc,dc,olcRootPW 几个值需要你自己改):
dn: olcDatabase={1}monitor,cn=config
changetype: modify
replace: olcAccess
olcAccess: {0}to * by dn.base="gidNumber=0+uidNumber=0,cn=peercred,cn=external,cn=auth"
read by dn.base="cn=gitnavi,dc=youmeek,dc=com" read by * none
dn: olcDatabase={2}hdb,cn=config
changetype: modify
replace: olcSuffix
olcSuffix: dc=youmeek,dc=com
dn: olcDatabase={2}hdb,cn=config
changetype: modify
replace: olcRootDN
olcRootDN: cn=gitnavi,dc=youmeek,dc=com
dn: olcDatabase={2}hdb,cn=config
changetype: modify
add: olcRootPW
olcRootPW: {SSHA}rNLkIMYKvYhbBjxLzSbjVsJnZSkrfC3w
dn: olcDatabase={2}hdb,cn=config
changetype: modify
add: olcAccess
olcAccess: {0}to attrs=userPassword,shadowLastChange by
dn="cn=gitnavi,dc=youmeek,dc=com" write by anonymous auth by self write by * none
olcAccess: {1}to dn.base="" by * read
olcAccess: {2}to * by dn="cn=gitnavi,dc=youmeek,dc=com" write by * read
- 添加配置:
ldapadd -Y EXTERNAL -H ldapi:/// -f chdomain.ldif
添加一个基本的目录
cd /root/my_ldif ; vim basedomain.ldif,添加如下内容(cn,dc,dc 几个值需要你自己改):
dn: dc=youmeek,dc=com
objectClass: top
objectClass: dcObject
objectclass: organization
o: youmeek dot Com
dc: youmeek
dn: cn=gitnavi,dc=youmeek,dc=com
objectClass: organizationalRole
cn: gitnavi
description: Directory Manager
dn: ou=People,dc=youmeek,dc=com
objectClass: organizationalUnit
ou: People
dn: ou=Group,dc=youmeek,dc=com
objectClass: organizationalUnit
ou: Group
- 添加配置:
ldapadd -x -D cn=gitnavi,dc=youmeek,dc=com -W -f basedomain.ldif,会提示让你输入配置 domain 的密码,我是:111111 简单的配置到此就好了
测试连接
- 重启下服务:
systemctl restart slapd - 本机测试,输入命令:
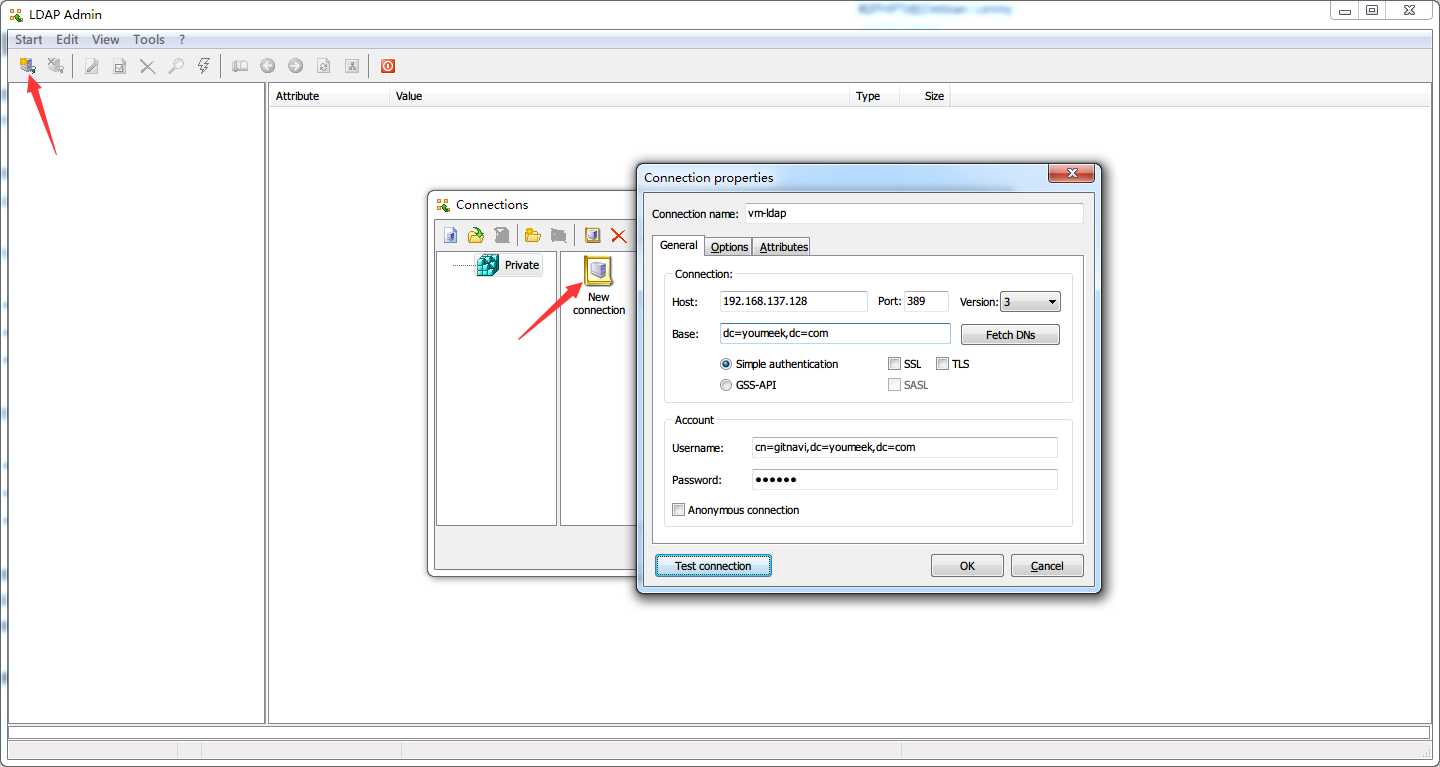
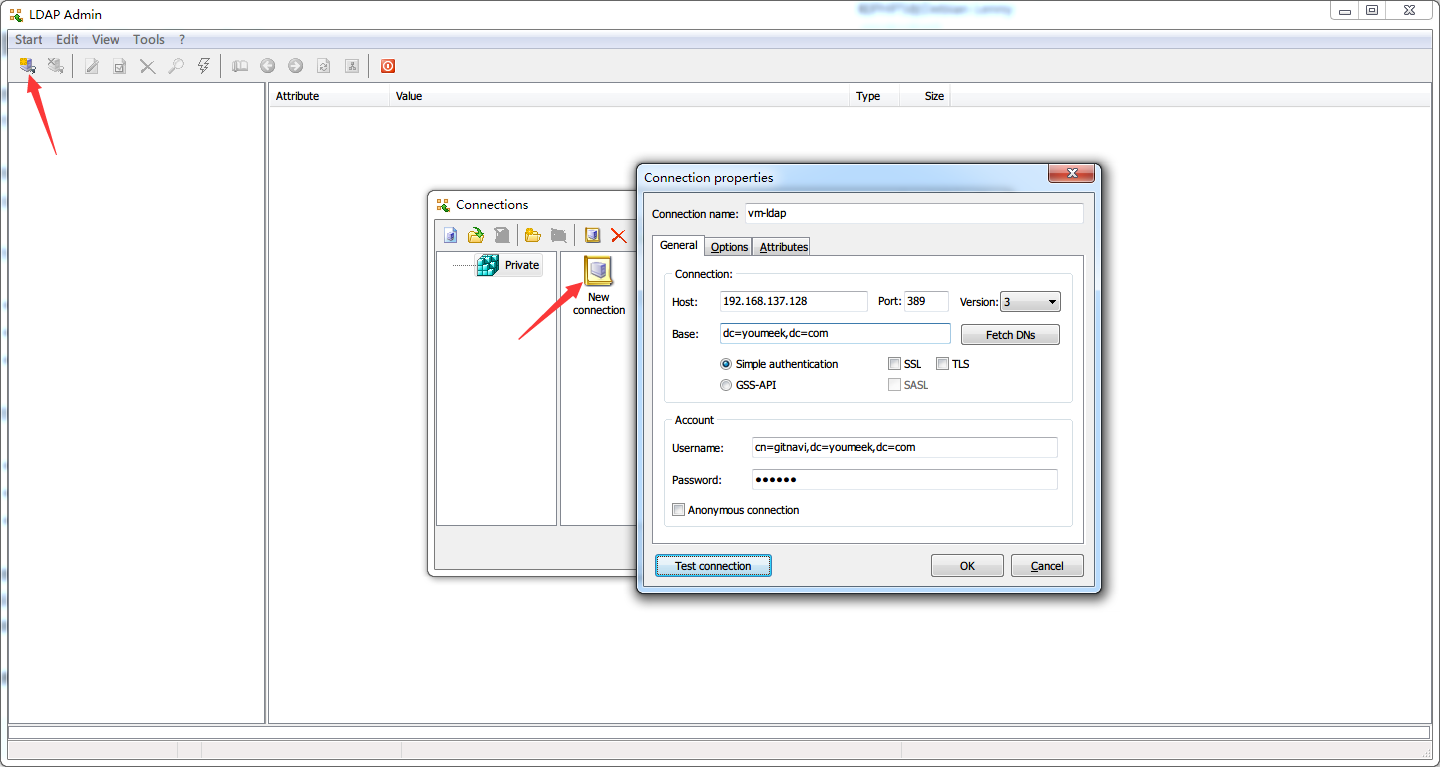
ldapsearch -LLL -W -x -D "cn=gitnavi,dc=youmeek,dc=com" -H ldap://localhost -b "dc=youmeek,dc=com",输入 domain 密码,可以查询到相应信息 - 局域网客户端连接测试,下载 Ldap Admin(下载地址看文章下面),具体连接信息看下图:
LDAP 客户端
资料
- https://superlc320.gitbooks.io/samba-ldap-centos7/ldap_+_centos_7.html
- http://yhz61010.iteye.com/blog/2352672
- https://kyligence.gitbooks.io/kap-manual/zh-cn/security/ldap.cn.html
- http://gaowenlong.blog.51cto.com/451336/1887408
Kubernets(K8S) 使用
环境说明
- CentOS 7.7(不准确地说:要求必须是 CentOS 7 64位)
- Docker
Kubernetes
- 目前流行的容器编排系统
- 简称:K8S
- 官网:https://kubernetes.io/
- 主要解决几个问题:
调度生命周期及健康状况服务发现监控认证容器聚合
- 主要角色:Master、Node
安装准备 - Kubernetes 1.13 版本
- 推荐最低 2C2G,优先:2C4G 或以上
- 特别说明:1.13 之前的版本,由于网络问题,需要各种设置,这里就不再多说了。1.13 之后相对就简单了点。
- 优先官网软件包:kubeadm
- 官网资料:
- issues 入口:https://github.com/kubernetes/kubeadm
- 源码入口:https://github.com/kubernetes/kubernetes/tree/master/cmd/kubeadm
- 安装指导:https://kubernetes.io/docs/setup/independent/install-kubeadm/
- 按官网要求做下检查:https://kubernetes.io/docs/setup/independent/install-kubeadm/#before-you-begin
- 网络环境:https://kubernetes.io/docs/setup/independent/install-kubeadm/#verify-the-mac-address-and-product-uuid-are-unique-for-every-node
- 端口检查:https://kubernetes.io/docs/setup/independent/install-kubeadm/#check-required-ports
- 对 Docker 版本的支持,这里官网推荐的是 18.06:https://kubernetes.io/docs/setup/release/notes/#sig-cluster-lifecycle
- 三大核心工具包,都需要各自安装,并且注意版本关系:
kubeadm: the command to bootstrap the cluster.- 集群部署、管理工具
kubelet: the component that runs on all of the machines in your cluster and does things like starting pods and containers.- 具体执行层面的管理 Pod 和 Docker 工具
kubectl: the command line util to talk to your cluster.- 操作 k8s 的命令行入口工具
- 官网插件安装过程的故障排查:https://kubernetes.io/docs/setup/independent/troubleshooting-kubeadm/
- 其他部署方案:
开始安装 - Kubernetes 1.13.3 版本
- 三台机子:
- master-1:
192.168.0.127 - node-1:
192.168.0.128 - node-2:
192.168.0.129
- master-1:
- 官网最新版本:https://github.com/kubernetes/kubernetes/releases
- 官网 1.13 版本的 changelog:https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG-1.13.md
- 所有节点安装 Docker 18.06,并设置阿里云源
- 可以参考:点击我o(∩_∩)o
- 核心,查看可以安装的 Docker 列表:
yum list docker-ce --showduplicates
- 所有节点设置 kubernetes repo 源,并安装 Kubeadm、Kubelet、Kubectl 都设置阿里云的源
- Kubeadm 初始化集群过程当中,它会下载很多的镜像,默认也是去 Google 家里下载。但是 1.13 新增了一个配置:
--image-repository算是救了命。
安装具体流程
- 同步所有机子时间:
systemctl start chronyd.service && systemctl enable chronyd.service - 所有机子禁用防火墙、selinux、swap
systemctl stop firewalld.service
systemctl disable firewalld.service
systemctl disable iptables.service
iptables -P FORWARD ACCEPT
setenforce 0 && sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
echo "vm.swappiness = 0" >> /etc/sysctl.conf
swapoff -a && sysctl -w vm.swappiness=0
- 给各自机子设置 hostname 和 hosts
hostnamectl --static set-hostname k8s-master-1
hostnamectl --static set-hostname k8s-node-1
hostnamectl --static set-hostname k8s-node-2
vim /etc/hosts
192.168.0.127 k8s-master-1
192.168.0.128 k8s-node-1
192.168.0.129 k8s-node-2
- 给 master 设置免密
ssh-keygen -t rsa
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
ssh localhost
ssh-copy-id -i ~/.ssh/id_rsa.pub -p 22 root@k8s-node-1(根据提示输入 k8s-node-1 密码)
ssh-copy-id -i ~/.ssh/id_rsa.pub -p 22 root@k8s-node-2(根据提示输入 k8s-node-2 密码)
ssh k8s-master-1
ssh k8s-node-1
ssh k8s-node-2
- 给所有机子设置 yum 源
vim /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
scp -r /etc/yum.repos.d/kubernetes.repo root@k8s-node-1:/etc/yum.repos.d/
scp -r /etc/yum.repos.d/kubernetes.repo root@k8s-node-2:/etc/yum.repos.d/
- 给 master 机子创建 flannel 配置文件
mkdir -p /etc/cni/net.d && vim /etc/cni/net.d/10-flannel.conflist
{
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
- 给所有机子创建配置
vim /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward=1
vm.swappiness=0
scp -r /etc/sysctl.d/k8s.conf root@k8s-node-1:/etc/sysctl.d/
scp -r /etc/sysctl.d/k8s.conf root@k8s-node-2:/etc/sysctl.d/
modprobe br_netfilter && sysctl -p /etc/sysctl.d/k8s.conf
- 给所有机子安装组件
yum install -y kubelet-1.13.3 kubeadm-1.13.3 kubectl-1.13.3 --disableexcludes=kubernetes
- 给所有机子添加一个变量
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
最后一行添加:Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=cgroupfs"
- 启动所有机子
systemctl enable kubelet && systemctl start kubelet
kubeadm version
kubectl version
- 初始化 master 节点:
echo 1 > /proc/sys/net/ipv4/ip_forward
kubeadm init \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--pod-network-cidr 10.244.0.0/16 \
--kubernetes-version 1.13.3 \
--ignore-preflight-errors=Swap
其中 10.244.0.0/16 是 flannel 插件固定使用的ip段,它的值取决于你准备安装哪个网络插件
这个过程会下载一些 docker 镜像,时间可能会比较久,看你网络情况。
终端会输出核心内容:
[init] Using Kubernetes version: v1.13.3
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Activating the kubelet service
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [k8s-master-1 localhost] and IPs [192.168.0.127 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [k8s-master-1 localhost] and IPs [192.168.0.127 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [k8s-master-1 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.0.127]
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 19.001686 seconds
[uploadconfig] storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.13" in namespace kube-system with the configuration for the kubelets in the cluster
[patchnode] Uploading the CRI Socket information "/var/run/dockershim.sock" to the Node API object "k8s-master-1" as an annotation
[mark-control-plane] Marking the node k8s-master-1 as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node k8s-master-1 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: 8tpo9l.jlw135r8559kaad4
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstraptoken] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstraptoken] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstraptoken] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstraptoken] creating the "cluster-info" ConfigMap in the "kube-public" namespace
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes master has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join 192.168.0.127:6443 --token 8tpo9l.jlw135r8559kaad4 --discovery-token-ca-cert-hash sha256:d6594ccc1310a45cbebc45f1c93f5ac113873786365ed63efcf667c952d7d197
- 给 master 机子设置配置
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
export KUBECONFIG=$HOME/.kube/config
- 在 master 上查看一些环境
kubeadm token list
kubectl cluster-info
- 给 master 安装 Flannel
cd /opt && wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f /opt/kube-flannel.yml
- 到 node 节点加入集群:
echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables
kubeadm join 192.168.0.127:6443 --token 8tpo9l.jlw135r8559kaad4 --discovery-token-ca-cert-hash sha256:d6594ccc1310a45cbebc45f1c93f5ac113873786365ed63efcf667c952d7d197
这时候终端会输出:
[preflight] Running pre-flight checks
[discovery] Trying to connect to API Server "192.168.0.127:6443"
[discovery] Created cluster-info discovery client, requesting info from "https://192.168.0.127:6443"
[discovery] Requesting info from "https://192.168.0.127:6443" again to validate TLS against the pinned public key
[discovery] Cluster info signature and contents are valid and TLS certificate validates against pinned roots, will use API Server "192.168.0.127:6443"
[discovery] Successfully established connection with API Server "192.168.0.127:6443"
[join] Reading configuration from the cluster...
[join] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[kubelet] Downloading configuration for the kubelet from the "kubelet-config-1.13" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Activating the kubelet service
[tlsbootstrap] Waiting for the kubelet to perform the TLS Bootstrap...
[patchnode] Uploading the CRI Socket information "/var/run/dockershim.sock" to the Node API object "k8s-node-1" as an annotation
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the master to see this node join the cluster.
- 如果 node 节点加入失败,可以:
kubeadm reset,再来重新 join - 在 master 节点上:
kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health": "true"}
结果都是 Healthy 则表示可以了,不然就得检查。必要时可以用:`kubeadm reset` 重置,重新进行集群初始化
- 在 master 节点上:
kubectl get nodes
如果还是 NotReady,则查看错误信息:kubectl get pods --all-namespaces
其中:Pending/ContainerCreating/ImagePullBackOff 都是 Pod 没有就绪,我们可以这样查看对应 Pod 遇到了什么问题
kubectl describe pod <Pod Name> --namespace=kube-system
或者:kubectl logs <Pod Name> -n kube-system
tail -f /var/log/messages
主要概念
-
Master 节点,负责集群的调度、集群的管理
- 常见组件:https://kubernetes.io/docs/concepts/overview/components/
- kube-apiserver:API服务
- kube-scheduler:调度
- Kube-Controller-Manager:容器编排
- Etcd:保存了整个集群的状态
- Kube-proxy:负责为 Service 提供 cluster 内部的服务发现和负载均衡
- Kube-DNS:负责为整个集群提供 DNS 服务
-
node 节点,负责容器相关的处理
-
Pods
创建,调度以及管理的最小单元
共存的一组容器的集合
容器共享PID,网络,IPC以及UTS命名空间
容器共享存储卷
短暂存在
Volumes
数据持久化
Pod中容器共享数据
生命周期
支持多种类型的数据卷 – emptyDir, hostpath, gcePersistentDisk, awsElasticBlockStore, nfs, iscsi, glusterfs, secrets
Labels
用以标示对象(如Pod)的key/value对
组织并选择对象子集
Replication Controllers
确保在任一时刻运行指定数目的Pod
容器重新调度
规模调整
在线升级
多发布版本跟踪
Services
抽象一系列Pod并定义其访问规则
固定IP地址和DNS域名
通过环境变量和DNS发现服务
负载均衡
外部服务 – ClusterIP, NodePort, LoadBalancer
主要组成模块
etcd
高可用的Key/Value存储
只有apiserver有读写权限
使用etcd集群确保数据可靠性
apiserver
Kubernetes系统入口, REST
认证
授权
访问控制
服务帐号
资源限制
kube-scheduler
资源需求
服务需求
硬件/软件/策略限制
关联性和非关联性
数据本地化
kube-controller-manager
Replication controller
Endpoint controller
Namespace controller
Serviceaccount controller
kubelet
节点管理器
确保调度到本节点的Pod的运行和健康
kube-proxy
Pod网络代理
TCP/UDP请求转发
负载均衡(Round Robin)
服务发现
环境变量
DNS – kube2sky, etcd,skydns
网络
容器间互相通信
节点和容器间互相通信
每个Pod使用一个全局唯一的IP
高可用
kubelet保证每一个master节点的服务正常运行
系统监控程序确保kubelet正常运行
Etcd集群
多个apiserver进行负载均衡
Master选举确保kube-scheduler和kube-controller-manager高可用
资料
Hadoop 安装和配置
Hadoop 说明
- Hadoop 官网:https://hadoop.apache.org/
- Hadoop 官网下载:https://hadoop.apache.org/releases.html
基础环境
- 学习机器 2C4G(生产最少 8G):
- 172.16.0.17
- 172.16.0.43
- 172.16.0.180
- 操作系统:CentOS 7.5
- root 用户
- 所有机子必备:Java:1.8
- 确保:
echo $JAVA_HOME能查看到路径,并记下来路径
- 确保:
- Hadoop:2.6.5
- 关闭所有机子的防火墙:
systemctl stop firewalld.service
集群环境设置
- Hadoop 集群具体来说包含两个集群:HDFS 集群和 YARN 集群,两者逻辑上分离,但物理上常在一起
- HDFS 集群:负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
- YARN 集群:负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
- HDFS 采用 master/worker 架构。一个 HDFS 集群是由一个 Namenode 和一定数目的 Datanodes 组成。Namenode 是一个中心服务器,负责管理文件系统的命名空间 (namespace) 以及客户端对文件的访问。集群中的 Datanode 一般是一个节点一个,负责管理它所在节点上的存储。
- 分别给三台机子设置 hostname
hostnamectl --static set-hostname linux01
hostnamectl --static set-hostname linux02
hostnamectl --static set-hostname linux03
- 修改 hosts
就按这个来,其他多余的别加,不然可能也会有影响
vim /etc/hosts
172.16.0.17 linux01
172.16.0.43 linux02
172.16.0.180 linux03
- 对 linux01 设置免密:
生产密钥对
ssh-keygen -t rsa
公钥内容写入 authorized_keys
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
测试:
ssh localhost
- 将公钥复制到两台 slave
- 如果你是采用 pem 登录的,可以看这个:SSH 免密登录
ssh-copy-id -i ~/.ssh/id_rsa.pub -p 22 root@172.16.0.43,根据提示输入 linux02 机器的 root 密码,成功会有相应提示
ssh-copy-id -i ~/.ssh/id_rsa.pub -p 22 root@172.16.0.180,根据提示输入 linux03 机器的 root 密码,成功会有相应提示
在 linux01 上测试:
ssh linux02
ssh linux03
Hadoop 安装
- 关于版本这件事,主要看你的技术生态圈。如果你的其他技术,比如 Spark,Flink 等不支持最新版,则就只能向下考虑。
- 我这里技术栈,目前只能到:2.6.5,所以下面的内容都是基于 2.6.5 版本
- 官网说明:https://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-common/ClusterSetup.html
- 分别在三台机子上都创建目录:
mkdir -p /data/hadoop/hdfs/name /data/hadoop/hdfs/data /data/hadoop/hdfs/tmp
- 下载 Hadoop:http://apache.claz.org/hadoop/common/hadoop-2.6.5/
- 现在 linux01 机子上安装
cd /usr/local && wget http://apache.claz.org/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
tar zxvf hadoop-2.6.5.tar.gz,有 191M 左右
- 给三台机子都先设置 HADOOP_HOME
- 会 ansible playbook 会方便点:Ansible 安装和配置
vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
修改 linux01 配置
修改 JAVA_HOME
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
把 25 行的
export JAVA_HOME=${JAVA_HOME}
都改为
export JAVA_HOME=/usr/local/jdk1.8.0_191
vim $HADOOP_HOME/etc/hadoop/yarn-env.sh
文件开头加一行 export JAVA_HOME=/usr/local/jdk1.8.0_191
- hadoop.tmp.dir == 指定hadoop运行时产生文件的存储目录
vim $HADOOP_HOME/etc/hadoop/core-site.xml,改为:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/data/hadoop/hdfs/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!--
<property>
<name>fs.default.name</name>
<value>hdfs://linux01:9000</value>
</property>
-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://linux01:9000</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
- 配置包括副本数量
- 最大值是 datanode 的个数
- 数据存放目录
vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
- 设置 YARN
新创建:vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>8192</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx3072m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx6144m</value>
</property>
</configuration>
- yarn.resourcemanager.hostname == 指定YARN的老大(ResourceManager)的地址
- yarn.nodemanager.aux-services == NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序默认值:""
- 32G 内存的情况下配置:
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>linux01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
</configuration>
- 配置 slave 相关信息
vim $HADOOP_HOME/etc/hadoop/slaves
把默认的配置里面的 localhost 删除,换成:
linux02
linux03
scp -r /usr/local/hadoop-2.6.5 root@linux02:/usr/local/
scp -r /usr/local/hadoop-2.6.5 root@linux03:/usr/local/
linux01 机子运行
格式化 HDFS
hdfs namenode -format
- 输出结果:
[root@linux01 hadoop-2.6.5]# hdfs namenode -format
18/12/17 17:47:17 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/127.0.0.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.6.5
STARTUP_MSG: classpath = /usr/local/hadoop-2.6.5/etc/hadoop:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/commons-io-2.4.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/activation-1.1.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/netty-3.6.2.Final.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/slf4j-api-1.7.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/junit-4.11.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/curator-recipes-2.6.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jasper-compiler-5.5.23.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jets3t-0.9.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/commons-lang-2.6.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/commons-digester-1.8.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/guava-11.0.2.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/gson-2.2.4.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jettison-1.1.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jetty-6.1.26.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/log4j-1.2.17.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/commons-httpclient-3.1.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/commons-el-1.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/paranamer-2.3.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/commons-collections-3.2.2.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jersey-server-1.9.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/commons-net-3.1.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/hadoop-auth-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jasper-runtime-5.5.23.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/hamcrest-core-1.3.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/stax-api-1.0-2.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/curator-framework-2.6.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/xz-1.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jsr305-1.3.9.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jsp-api-2.1.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/commons-compress-1.4.1.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/asm-3.2.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jsch-0.1.42.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/commons-configuration-1.6.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/commons-cli-1.2.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/commons-logging-1.1.3.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/htrace-core-3.0.4.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jetty-util-6.1.26.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/commons-math3-3.1.1.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/mockito-all-1.8.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jersey-json-1.9.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/zookeeper-3.4.6.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/httpclient-4.2.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/servlet-api-2.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/xmlenc-0.52.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/httpcore-4.2.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/avro-1.7.4.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/commons-codec-1.4.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/jersey-core-1.9.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/curator-client-2.6.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/hadoop-annotations-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/hadoop-common-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/hadoop-common-2.6.5-tests.jar:/usr/local/hadoop-2.6.5/share/hadoop/common/hadoop-nfs-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/commons-io-2.4.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/guava-11.0.2.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/commons-el-1.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/jasper-runtime-5.5.23.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/jsr305-1.3.9.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/jsp-api-2.1.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/asm-3.2.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/htrace-core-3.0.4.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/hadoop-hdfs-2.6.5-tests.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/hadoop-hdfs-nfs-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/hadoop-hdfs-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/commons-io-2.4.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/activation-1.1.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/aopalliance-1.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/commons-lang-2.6.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/guice-3.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/guava-11.0.2.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/jettison-1.1.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/jetty-6.1.26.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/log4j-1.2.17.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/commons-httpclient-3.1.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/commons-collections-3.2.2.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/jersey-server-1.9.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/xz-1.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/jsr305-1.3.9.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/jersey-client-1.9.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/asm-3.2.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/commons-cli-1.2.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/jersey-json-1.9.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/javax.inject-1.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/servlet-api-2.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/jline-0.9.94.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/commons-codec-1.4.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/jersey-core-1.9.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/hadoop-yarn-api-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/hadoop-yarn-server-common-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/hadoop-yarn-registry-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/hadoop-yarn-client-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/hadoop-yarn-common-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/hadoop-yarn-server-tests-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/junit-4.11.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/guice-3.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/xz-1.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/asm-3.2.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/javax.inject-1.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/hadoop-annotations-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.5-tests.jar:/usr/local/hadoop-2.6.5/contrib/capacity-scheduler/*.jar
STARTUP_MSG: build = https://github.com/apache/hadoop.git -r e8c9fe0b4c252caf2ebf1464220599650f119997; compiled by 'sjlee' on 2016-10-02T23:43Z
STARTUP_MSG: java = 1.8.0_191
************************************************************/
18/12/17 17:47:17 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
18/12/17 17:47:17 INFO namenode.NameNode: createNameNode [-format]
Formatting using clusterid: CID-beba43b4-0881-48b4-8eda-5c3bca046398
18/12/17 17:47:17 INFO namenode.FSNamesystem: No KeyProvider found.
18/12/17 17:47:17 INFO namenode.FSNamesystem: fsLock is fair:true
18/12/17 17:47:17 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
18/12/17 17:47:17 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
18/12/17 17:47:17 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
18/12/17 17:47:17 INFO blockmanagement.BlockManager: The block deletion will start around 2018 Dec 17 17:47:17
18/12/17 17:47:17 INFO util.GSet: Computing capacity for map BlocksMap
18/12/17 17:47:17 INFO util.GSet: VM type = 64-bit
18/12/17 17:47:17 INFO util.GSet: 2.0% max memory 889 MB = 17.8 MB
18/12/17 17:47:17 INFO util.GSet: capacity = 2^21 = 2097152 entries
18/12/17 17:47:17 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
18/12/17 17:47:17 INFO blockmanagement.BlockManager: defaultReplication = 2
18/12/17 17:47:17 INFO blockmanagement.BlockManager: maxReplication = 512
18/12/17 17:47:17 INFO blockmanagement.BlockManager: minReplication = 1
18/12/17 17:47:17 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
18/12/17 17:47:17 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
18/12/17 17:47:17 INFO blockmanagement.BlockManager: encryptDataTransfer = false
18/12/17 17:47:17 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
18/12/17 17:47:17 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE)
18/12/17 17:47:17 INFO namenode.FSNamesystem: supergroup = supergroup
18/12/17 17:47:17 INFO namenode.FSNamesystem: isPermissionEnabled = false
18/12/17 17:47:17 INFO namenode.FSNamesystem: HA Enabled: false
18/12/17 17:47:17 INFO namenode.FSNamesystem: Append Enabled: true
18/12/17 17:47:17 INFO util.GSet: Computing capacity for map INodeMap
18/12/17 17:47:17 INFO util.GSet: VM type = 64-bit
18/12/17 17:47:17 INFO util.GSet: 1.0% max memory 889 MB = 8.9 MB
18/12/17 17:47:17 INFO util.GSet: capacity = 2^20 = 1048576 entries
18/12/17 17:47:17 INFO namenode.NameNode: Caching file names occuring more than 10 times
18/12/17 17:47:17 INFO util.GSet: Computing capacity for map cachedBlocks
18/12/17 17:47:17 INFO util.GSet: VM type = 64-bit
18/12/17 17:47:17 INFO util.GSet: 0.25% max memory 889 MB = 2.2 MB
18/12/17 17:47:17 INFO util.GSet: capacity = 2^18 = 262144 entries
18/12/17 17:47:17 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
18/12/17 17:47:17 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
18/12/17 17:47:17 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
18/12/17 17:47:17 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
18/12/17 17:47:17 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
18/12/17 17:47:17 INFO util.GSet: Computing capacity for map NameNodeRetryCache
18/12/17 17:47:17 INFO util.GSet: VM type = 64-bit
18/12/17 17:47:17 INFO util.GSet: 0.029999999329447746% max memory 889 MB = 273.1 KB
18/12/17 17:47:17 INFO util.GSet: capacity = 2^15 = 32768 entries
18/12/17 17:47:17 INFO namenode.NNConf: ACLs enabled? false
18/12/17 17:47:17 INFO namenode.NNConf: XAttrs enabled? true
18/12/17 17:47:17 INFO namenode.NNConf: Maximum size of an xattr: 16384
18/12/17 17:47:17 INFO namenode.FSImage: Allocated new BlockPoolId: BP-233285725-127.0.0.1-1545040037972
18/12/17 17:47:18 INFO common.Storage: Storage directory /data/hadoop/hdfs/name has been successfully formatted.
18/12/17 17:47:18 INFO namenode.FSImageFormatProtobuf: Saving image file /data/hadoop/hdfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
18/12/17 17:47:18 INFO namenode.FSImageFormatProtobuf: Image file /data/hadoop/hdfs/name/current/fsimage.ckpt_0000000000000000000 of size 321 bytes saved in 0 seconds.
18/12/17 17:47:18 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
18/12/17 17:47:18 INFO util.ExitUtil: Exiting with status 0
18/12/17 17:47:18 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/127.0.0.1
************************************************************/
HDFS 启动
- 启动:start-dfs.sh,根据提示一路 yes
这个命令效果:
主节点会启动任务:NameNode 和 SecondaryNameNode
从节点会启动任务:DataNode
主节点查看:jps,可以看到:
21922 Jps
21603 NameNode
21787 SecondaryNameNode
从节点查看:jps 可以看到:
19728 DataNode
19819 Jps
- 查看运行更多情况:
hdfs dfsadmin -report
Configured Capacity: 0 (0 B)
Present Capacity: 0 (0 B)
DFS Remaining: 0 (0 B)
DFS Used: 0 (0 B)
DFS Used%: NaN%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
- 如果需要停止:
stop-dfs.sh - 查看 log:
cd $HADOOP_HOME/logs
YARN 运行
start-yarn.sh
然后 jps 你会看到一个:ResourceManager
从节点你会看到:NodeManager
停止:stop-yarn.sh
端口情况
- 主节点当前运行的所有端口:
netstat -tpnl | grep java - 会用到端口(为了方便展示,整理下顺序):
tcp 0 0 172.16.0.17:9000 0.0.0.0:* LISTEN 22932/java >> NameNode
tcp 0 0 0.0.0.0:50070 0.0.0.0:* LISTEN 22932/java >> NameNode
tcp 0 0 0.0.0.0:50090 0.0.0.0:* LISTEN 23125/java >> SecondaryNameNode
tcp6 0 0 172.16.0.17:8030 :::* LISTEN 23462/java >> ResourceManager
tcp6 0 0 172.16.0.17:8031 :::* LISTEN 23462/java >> ResourceManager
tcp6 0 0 172.16.0.17:8032 :::* LISTEN 23462/java >> ResourceManager
tcp6 0 0 172.16.0.17:8033 :::* LISTEN 23462/java >> ResourceManager
tcp6 0 0 172.16.0.17:8088 :::* LISTEN 23462/java >> ResourceManager
- 从节点当前运行的所有端口:
netstat -tpnl | grep java - 会用到端口(为了方便展示,整理下顺序):
tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN 14545/java >> DataNode
tcp 0 0 0.0.0.0:50020 0.0.0.0:* LISTEN 14545/java >> DataNode
tcp 0 0 0.0.0.0:50075 0.0.0.0:* LISTEN 14545/java >> DataNode
tcp6 0 0 :::8040 :::* LISTEN 14698/java >> NodeManager
tcp6 0 0 :::8042 :::* LISTEN 14698/java >> NodeManager
tcp6 0 0 :::13562 :::* LISTEN 14698/java >> NodeManager
tcp6 0 0 :::37481 :::* LISTEN 14698/java >> NodeManager
管理界面
- 查看 HDFS NameNode 管理界面:http://linux01:50070
- 访问 YARN ResourceManager 管理界面:http://linux01:8088
- 访问 NodeManager-1 管理界面:http://linux02:8042
- 访问 NodeManager-2 管理界面:http://linux03:8042
运行作业
- 在主节点上操作
- 运行一个 Mapreduce 作业试试:
- 计算 π:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar pi 5 10
- 计算 π:
- 运行一个文件相关作业:
- 由于运行 hadoop 时指定的输入文件只能是 HDFS 文件系统中的文件,所以我们必须将要进行 wordcount 的文件从本地文件系统拷贝到 HDFS 文件系统中。
- 查看目前根目录结构:
hadoop fs -ls /- 查看目前根目录结构,另外写法:
hadoop fs -ls hdfs://linux-05:9000/ - 或者列出目录以及下面的文件:
hadoop fs -ls -R / - 更多命令可以看:hadoop HDFS常用文件操作命令
- 查看目前根目录结构,另外写法:
- 创建目录:
hadoop fs -mkdir -p /tmp/zch/wordcount_input_dir - 上传文件:
hadoop fs -put /opt/input.txt /tmp/zch/wordcount_input_dir - 查看上传的目录下是否有文件:
hadoop fs -ls /tmp/zch/wordcount_input_dir - 向 yarn 提交作业,计算单词个数:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount /tmp/zch/wordcount_input_dir /tmp/zch/wordcount_output_dir - 查看计算结果输出的目录:
hadoop fs -ls /tmp/zch/wordcount_output_dir - 查看计算结果输出内容:
hadoop fs -cat /tmp/zch/wordcount_output_dir/part-r-00000
- 查看正在运行的 Hadoop 任务:
yarn application -list - 关闭 Hadoop 任务进程:
yarn application -kill 你的ApplicationId
资料
- 如何正确的为 MapReduce 配置内存分配
- https://www.linode.com/docs/databases/hadoop/how-to-install-and-set-up-hadoop-cluster/
- http://www.cnblogs.com/Leo_wl/p/7426496.html
- https://blog.csdn.net/bingduanlbd/article/details/51892750
- https://blog.csdn.net/whdxjbw/article/details/81050597
Gitlab 安装和配置
Docker Compose 安装方式
- 创建宿主机挂载目录:
mkdir -p /data/docker/gitlab/gitlab /data/docker/gitlab/redis /data/docker/gitlab/postgresql - 赋权(避免挂载的时候,一些程序需要容器中的用户的特定权限使用):
chown -R 777 /data/docker/gitlab/gitlab /data/docker/gitlab/redis /data/docker/gitlab/postgresql - 这里使用 docker-compose 的启动方式,所以需要创建 docker-compose.yml 文件:
gitlab:
image: sameersbn/gitlab:10.4.2-1
ports:
- "10022:22"
- "10080:80"
links:
- gitlab-redis:redisio
- gitlab-postgresql:postgresql
environment:
- GITLAB_PORT=80
- GITLAB_SSH_PORT=22
- GITLAB_SECRETS_DB_KEY_BASE=long-and-random-alpha-numeric-string
- GITLAB_SECRETS_SECRET_KEY_BASE=long-and-random-alpha-numeric-string
- GITLAB_SECRETS_OTP_KEY_BASE=long-and-random-alpha-numeric-string
volumes:
- /data/docker/gitlab/gitlab:/home/git/data
restart: always
gitlab-redis:
image: sameersbn/redis
volumes:
- /data/docker/gitlab/redis:/var/lib/redis
restart: always
gitlab-postgresql:
image: sameersbn/postgresql:9.6-2
environment:
- DB_NAME=gitlabhq_production
- DB_USER=gitlab
- DB_PASS=password
- DB_EXTENSION=pg_trgm
volumes:
- /data/docker/gitlab/postgresql:/var/lib/postgresql
restart: always
- 启动:
docker-compose up -d - 浏览器访问:http://192.168.0.105:10080
Gitlab 高可用方案(High Availability)
- 官网:https://about.gitlab.com/high-availability/
- 本质就是把文件、缓存、数据库抽离出来,然后部署多个 Gitlab 用 nginx 前面做负载。
原始安装方式(推荐)
- 推荐至少内存 4G,它有大量组件
- 有开源版本和收费版本,各版本比较:https://about.gitlab.com/products/
- 官网:https://about.gitlab.com/
- 中文网:https://www.gitlab.com.cn/
- 官网下载:https://about.gitlab.com/downloads/
- 官网安装说明:https://about.gitlab.com/installation/#centos-7
- 如果上面的下载比较慢,也有国内的镜像:
- 参考:https://ken.io/note/centos7-gitlab-install-tutorial
sudo yum install -y curl policycoreutils-python openssh-server
sudo systemctl enable sshd
sudo systemctl start sshd
curl https://packages.gitlab.com/install/repositories/gitlab/gitlab-ce/script.rpm.sh | sudo bash
sudo EXTERNAL_URL="http://192.168.1.123:8181" yum install -y gitlab-ce
配置
- 配置域名 / IP
- 编辑配置文件:
sudo vim /etc/gitlab/gitlab.rb - 找到 13 行左右:
external_url 'http://gitlab.example.com',改为你的域名 / IP - 刷新配置:
sudo gitlab-ctl reconfigure,第一次这个时间会比较久,我花了好几分钟 - 启动服务:
sudo gitlab-ctl start - 停止服务:
sudo gitlab-ctl stop - 重启服务:
sudo gitlab-ctl restart
- 编辑配置文件:
- 前面的初始化配置完成之后,访问当前机子 IP:
http://192.168.1.111:80 - 默认用户是
root,并且没有密码,所以第一次访问是让你设置你的 root 密码,我设置为:gitlab123456(至少 8 位数) - 设置会初始化密码之后,你就需要登录了。输入设置的密码。
- root 管理员登录之后常用的设置地址(请求地址都是 RESTful 风格很好懂,也应该不会再变了。):
- 用户管理:http://192.168.1.111/admin/users
- 用户组管理:http://192.168.1.111/admin/groups
- 项目管理:http://192.168.1.111/admin/projects
- 添加 SSH Keys:http://192.168.1.111/profile/keys
- 给新创建的用户设置密码:http://192.168.1.111/admin/users/用户名/edit
- 新创建的用户,他首次登录会要求他强制修改密码的,这个设定很棒!
- 普通用户登录之后常去的链接:
- 配置 SSH Keys:http://192.168.1.111/profile/keys
配置 Jenkins 拉取代码权限
- Gitlab 创建一个 Access Token:http://192.168.0.105:10080/profile/personal_access_tokens
- 填写任意 Name 字符串
- 勾选:API
Access the authenticated user's API - 点击:Create personal access token,会生成一个类似格式的字符串:
wt93jQzA8yu5a6pfsk3s,这个 Jenkinsfile 会用到
- 先访问 Jenkins 插件安装页面,安装下面三个插件:http://192.168.0.105:18080/pluginManager/available
- Gitlab:可能会直接安装不成功,如果不成功根据报错的详细信息可以看到 hpi 文件的下载地址,挂代理下载下来,然后离线安装即可
- Gitlab Hook:用于触发 GitLab 的一些 WebHooks 来构建项目
- Gitlab Authentication 这个插件提供了使用GitLab进行用户认证和授权的方案
- 安装完插件后,访问 Jenkins 这个路径(Jenkins-->Credentials-->System-->Global credentials(unrestricted)-->Add Credentials)
- 该路径链接地址:http://192.168.0.105:18080/credentials/store/system/domain/_/newCredentials
- kind 下拉框选择:
GitLab API token - token 就填写我们刚刚生成的 access token
- ID 填写我们 Gitlab 账号
权限
- 官网帮助文档的权限说明:http://192.168.1.111/help/user/permissions
用户组的权限
- 用户组有这几种权限的概念:
Guest、Reporter、Developer、Master、Owner - 这个概念在设置用户组的时候会遇到,叫做:
Add user(s) to the group,比如链接:http://192.168.1.111/admin/groups/组名称
| 行为 | Guest | Reporter | Developer | Master | Owner |
|---|---|---|---|---|---|
| 浏览组 | ✓ | ✓ | ✓ | ✓ | ✓ |
| 编辑组 | ✓ | ||||
| 创建项目 | ✓ | ✓ | |||
| 管理组成员 | ✓ | ||||
| 移除组 | ✓ |
项目组的权限
- 项目组也有这几种权限的概念:
Guest、Reporter、Developer、Master、OwnerGuest:访客Reporter:报告者; 可以理解为测试员、产品经理等,一般负责提交issue等Developer:开发者; 负责开发Master:主人; 一般是组长,负责对Master分支进行维护Owner:拥有者; 一般是项目经理
- 这个概念在项目设置的时候会遇到,叫做:
Members,比如我有一个组下的项目链接:http://192.168.1.111/组名称/项目名称/settings/members
| 行为 | Guest | Reporter | Developer | Master | Owner |
|---|---|---|---|---|---|
| 创建issue | ✓ | ✓ | ✓ | ✓ | ✓ |
| 留言评论 | ✓ | ✓ | ✓ | ✓ | ✓ |
| 更新代码 | ✓ | ✓ | ✓ | ✓ | |
| 下载工程 | ✓ | ✓ | ✓ | ✓ | |
| 创建代码片段 | ✓ | ✓ | ✓ | ✓ | |
| 创建合并请求 | ✓ | ✓ | ✓ | ||
| 创建新分支 | ✓ | ✓ | ✓ | ||
| 提交代码到非保护分支 | ✓ | ✓ | ✓ | ||
| 强制提交到非保护分支 | ✓ | ✓ | ✓ | ||
| 移除非保护分支 | ✓ | ✓ | ✓ | ||
| 添加tag | ✓ | ✓ | ✓ | ||
| 创建wiki | ✓ | ✓ | ✓ | ||
| 管理issue处理者 | ✓ | ✓ | ✓ | ||
| 管理labels | ✓ | ✓ | ✓ | ||
| 创建里程碑 | ✓ | ✓ | |||
| 添加项目成员 | ✓ | ✓ | |||
| 提交保护分支 | ✓ | ✓ | |||
| 使能分支保护 | ✓ | ✓ | |||
| 修改/移除tag | ✓ | ✓ | |||
| 编辑工程 | ✓ | ✓ | |||
| 添加deploy keys | ✓ | ✓ | |||
| 配置hooks | ✓ | ✓ | |||
| 切换visibility level | ✓ | ||||
| 切换工程namespace | ✓ | ||||
| 移除工程 | ✓ | ||||
| 强制提交保护分支 | ✓ | ||||
| 移除保护分支 | ✓ |
批量从一个项目中的成员转移到另外一个项目
- 项目的设置地址:http://192.168.1.111/组名称/项目名称/settings/members
- 有一个 Import 按钮,跳转到:http://192.168.1.111/组名称/项目名称/project_members/import
限定哪些分支可以提交、可以 merge
- 也是在项目设置里面:http://192.168.1.111/组名称/项目名称/settings/repository#
- 设置 CI (持续集成) 的 key 也是在这个地址上设置。
Gitlab 的其他功能使用
创建用户
- 地址:http://119.23.252.150:10080/admin/users/
- 创建用户是没有填写密码的地方,默认是创建后会发送邮件给用户进行首次使用的密码设置。但是,有时候没必要这样,你可以创建好用户之后,编辑该用户就可以强制设置密码了(即使你设置了,第一次用户使用还是要让你修改密码...真是严苛)
创建群组
- 地址:http://119.23.252.150:10080/groups
- 群组主要有三种 Visibility Level:
- Private(私有,内部成员才能看到),The group and its projects can only be viewed by members.
- Internal(内部,只要能登录 Gitlab 就可以看到),The group and any internal projects can be viewed by any logged in user.
- Public(所有人都可以看到),The group and any public projects can be viewed without any authentication.
创建项目
增加 SSH keys
- 地址:http://119.23.252.150:10080/profile/keys
- 官网指导:http://119.23.252.150:10080/help/ssh/README
- 新增 SSH keys:
ssh-keygen -t rsa -C "gitnavi@qq.com" -b 4096 - linux 读取 SSH keys 值:
cat ~/.ssh/id_rsa.pub,复制到 gitlab 配置页面
使用 Gitlab 的一个开发流程 - Git flow
- Git flow:我是翻译成:Git 开发流程建议(不是规范,适合大点的团队),也有一个插件叫做这个,本质是用插件来帮你引导做规范的流程管理。
- 这几篇文章很好,不多说了:
- 比较起源的一个说明(英文):http://nvie.com/posts/a-successful-git-branching-model/
- Git-flow 插件也是他开发的,插件地址:https://github.com/nvie/gitflow
- Git-flow 插件的一些相关资料:
- http://www.ruanyifeng.com/blog/2015/12/git-workflow.html
- https://zhangmengpl.gitbooks.io/gitlab-guide/content/whatisgitflow.html
- http://blog.jobbole.com/76867/
- http://www.cnblogs.com/cnblogsfans/p/5075073.html
- 比较起源的一个说明(英文):http://nvie.com/posts/a-successful-git-branching-model/
接入第三方登录
-
官网文档:
-
gitlab 自己本身维护一套用户系统,第三方认证服务一套用户系统,gitlab 可以将两者关联起来,然后用户可以选择其中一种方式进行登录而已。
-
所以,gitlab 第三方认证只能用于网页登录,clone 时仍然使用用户在 gitlab 的账户密码,推荐使用 ssh-key 来操作仓库,不再使用账户密码。
-
重要参数:block_auto_created_users=true 的时候则自动注册的账户是被锁定的,需要管理员账户手动的为这些账户解锁,可以改为 false
-
编辑配置文件引入第三方:
sudo vim /etc/gitlab/gitlab.rb,在 309 行有默认的一些注释配置- 其中 oauth2_generic 模块默认是没有,需要自己 gem,其他主流的那些都自带,配置即可使用。
gitlab_rails['omniauth_enabled'] = true
gitlab_rails['omniauth_allow_single_sign_on'] = ['google_oauth2', 'facebook', 'twitter', 'oauth2_generic']
gitlab_rails['omniauth_block_auto_created_users'] = false
gitlab_rails['omniauth_sync_profile_attributes'] = ['email','username']
gitlab_rails['omniauth_external_providers'] = ['google_oauth2', 'facebook', 'twitter', 'oauth2_generic']
gitlab_rails['omniauth_providers'] = [
{
"name"=> "google_oauth2",
"label"=> "Google",
"app_id"=> "123456",
"app_secret"=> "123456",
"args"=> {
"access_type"=> 'offline',
"approval_prompt"=> '123456'
}
},
{
"name"=> "facebook",
"label"=> "facebook",
"app_id"=> "123456",
"app_secret"=> "123456"
},
{
"name"=> "twitter",
"label"=> "twitter",
"app_id"=> "123456",
"app_secret"=> "123456"
},
{
"name" => "oauth2_generic",
"app_id" => "123456",
"app_secret" => "123456",
"args" => {
client_options: {
"site" => "http://sso.cdk8s.com:9090/sso",
"user_info_url" => "/oauth/userinfo"
},
user_response_structure: {
root_path: ["user_attribute"],
attributes: {
"nickname": "username"
}
}
}
}
]
资料
- http://blog.smallmuou.xyz/git/2016/03/11/关于Gitlab若干权限问题.html
- https://zhangmengpl.gitbooks.io/gitlab-guide/content/whatisgitflow.html
- https://blog.coderstory.cn/2017/02/01/gitlab/
- https://xuanwo.org/2016/04/13/gitlab-install-intro/
- https://softlns.github.io/2016/11/14/jenkins-gitlab-docker/
Rinetd:一个用户端口重定向工具
Rinetd:一个用户端口重定向工具
概述
Rinetd 是一个 TCP 连接重定向工具,当我们需要进行流量的代理转发的时候,我们可以通过该工具完成。Rinetd 是一个使用异步 IO 的单进程的服务,它可以处理配置在 /etc/rinetd.conf 中的任意数量的连接,但是并不会过多的消耗服务器的资源。Rinetd 不能用于重定向 FTP 服务,因为 FTP 服务使用了多个 socket 进行通讯。
如果需要 Rinetd 随系统启动一起启动,可以在 /etc/rc.local 中添加启动命令 /usr/sbin/rinetd。在没有使用 -c 选项指定其他配置文件的情况下,Rinetd 使用默认的配置文件 /etc/rinetd.conf。
快速使用
git clone https://github.com/boutell/rinetd.git
cd rinetd
make && make install
echo "0.0.0.0 8080 www.baidu.com 80" > /etc/rinetd.conf
rinetd -c /etc/rinetd.conf
这里所有对 Rinetd 宿主机 8080 端口的请求都会被转发到 Baidu 上,注意: 保指定的端口没有被其他应用占用,如上面的 8080 端口。使用 kill -1 信号可以使 Rinetd 重新加载配置信息而不中断现有的连接。
转发规则
Rinetd 的大部分配置都是配置转发规则,规则如下:
bindaddress bindport connectaddress connectport
源地址 源端口 目的地址 目的端口
这里的地址可以是主机名也可以是 IP 地址。
如要将对 192.1.1.10:8080 的请求代理到 http://www.example.com:80 上,参照上面的规则配置如下:
www.example.com 80 192.1.1.10:8080
这里将对外的服务地址 http://www.example.com 重定向到了内部地址 192.1.1.10 的 8080 端口上。通常 192.1.1.10:8080 在防火墙的内部,外部请求并不能直接访问。如果我们源地址使用 IP 地址 0.0.0.0 ,那么代表将该服务器所有 IP 地址对应端口上的请求都代理到目的地址上。
权限控制
Rinetd 使用 allow pattern 和 deny pattern 两个关键字进行访问权限的控制。如:
allow 192.1.5.*
deny 192.1.5.1
这里 pattern 的内容必须是一个 IP 地址,不能是主机名或者域名。可以使用 ? 匹配 0 - 9 的任意一个字符,使用 * 匹配 0 -9 的任意个的字符。在转发规则之前配置的权限规则会作为一个全局生效的规则生效,在转发规则之后配置的权限规则仅适用于本条转发规则。校验的过程是先校验是否能够通过全局规则,再校验特定的规则。
日志收集
Rinetd 可以产生使用制表符分隔的日志或者 Web 服务器下的通用日志格式。默认情况下,Rinetd 不产生日志,如果需要获取日志,需要添加配置:
logfile /var/log/rinetd.log
如果需要采集 Web 通用格式的日志,需要添加配置:
gcommon
Linux 实践
Unix 特点:多用户多任务;命令行界面;简单、通用、高效; Linux 是一个多用户多任务的操作系统,也是一款自由软件,拥有良好的用户界面, 支持多种处理器架构,移植方便。 严格的来讲,Linux 并不算是一个操作系统,只是一个 Linux 系统中的内核,即计算 机软件与硬件通讯之间的平台; Linux的全称是GNU/Linux,这才算是一个真正意义上的Linux系统。 设计原则:1)所有的东西都是文件,所以管理简单 2)所有操作系统配置数据都存储在正文文件中 3)每个操作系统命令或应用程序很小,只完成单一功能 4)避免使用俘获用户的接口,很少交互命令,应用程序由vi编辑器等完成交互 5)多个程序串接在一起完成复杂任务
Error: ENOSPC: System limit for number of file watchers reached
在使用Ubuntu进行开发时,会遇到这个错误!
Error: ENOSPC: System limit for number of file watchers reached,
这个错误的意思时系统对文件监控的数量已经到达限制数量了!!
造成的结果: 执行的命令失败!或抛出警告(比如执行 react-native start 或者打开 vsocde)
解决方法:
修改系统监控文件数量
Ubuntu
sudo vim /etc/sysctl.conf
添加一行在最下面
fs.inotify.max_user_watches = 524288
执行
sudo sysctl -p
参考:
https://blog.csdn.net/weixin_30640291/article/details/94920800
https://www.cnblogs.com/or2-/p/10461045.html
https://www.jianshu.com/p/4d2edd55b471
https://blog.csdn.net/weixin_43760383/article/details/84326032
使用Nginx转发TCP/UDP
使用Nginx转发TCP/UDP
环境
- CentOS Linux release 7.7.1908 (Core)
- Nginx: 1.19.2
编译安装Nginx
从1.9.0开始,nginx就支持对TCP的转发,而到了1.9.13时,UDP转发也支持了。提供此功能的模块为ngx_stream_core。不过Nginx默认没有开启此模块,所以需要手动安装。
# http://nginx.org/download/
cd /usr/local/src
wget http://nginx.org/download/nginx-1.19.2.tar.gz
tar zxf nginx-1.19.2.tar.gz
cd nginx-1.19.2
./configure --prefix=/usr/local/nginx --with-stream --without-http
make && make install
Note:由于是传输层转发,本着最小化原则,就关闭了http功能。
配置Nginx
TCP转发
目标:通过3000端口访问本机Mysql(其中mysql使用yum安装,默认配置文件)
/usr/local/nginx/conf/nginx.conf配置如下:
user nobody;
worker_processes auto;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
events {
use epoll;
worker_connections 1024;
}
stream {
server {
listen 3000;
proxy_pass 127.0.0.1:3306;
# 也支持socket
# proxy_pass unix:/var/lib/mysql/mysql.socket;
}
}
首先,先通过3306端口访问mysql:

然后,启动Nginx:

最后使用3000端口访问mysql:
UDP转发
目标: 发送UDP数据到3000端口,3001端口可以接收
/usr/local/nginx/conf/nginx.conf配置如下:
user nobody;
worker_processes auto;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
events {
use epoll;
worker_connections 1024;
}
stream {
server {
listen 3000 udp;
proxy_pass 127.0.0.1:3001;
}
}
这里写一个my_socket_server.py侦听在3001端口,用于接收UDP数据:
# coding=utf-8
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
sock.bind(('127.0.0.1', 3001))
print ('start server on [%s]:%s' % ('127.0.0.1', 3001))
while True:
data, addr = sock.recvfrom(1024)
print ('Received from %s:%s' % (addr,data))
sock.sendto(b'Hello, %s!' % data, addr)
再写一个my_socket_client.py用于向Nginx侦听的3000端口发送数据:
# coding=utf-8
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
while True:
data = raw_input('Input msg: ')
if len(data) == 0:
continue
s.sendto(data.encode(), ('127.0.0.1', 3000))
print (s.recv(1024).decode('utf-8'))
同时运行两个脚本,在client端发送数据:

UDP转发遇到的一个坑
修改下client脚本,改为连续发送2000个数据包:
# coding=utf-8
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
for data in range(2000):
s.sendto(str(data).encode(), ('127.0.0.1', 3000))
print (s.recv(1024).decode('utf-8'))
然后运行client脚本,发现经常会遇到如下情况:
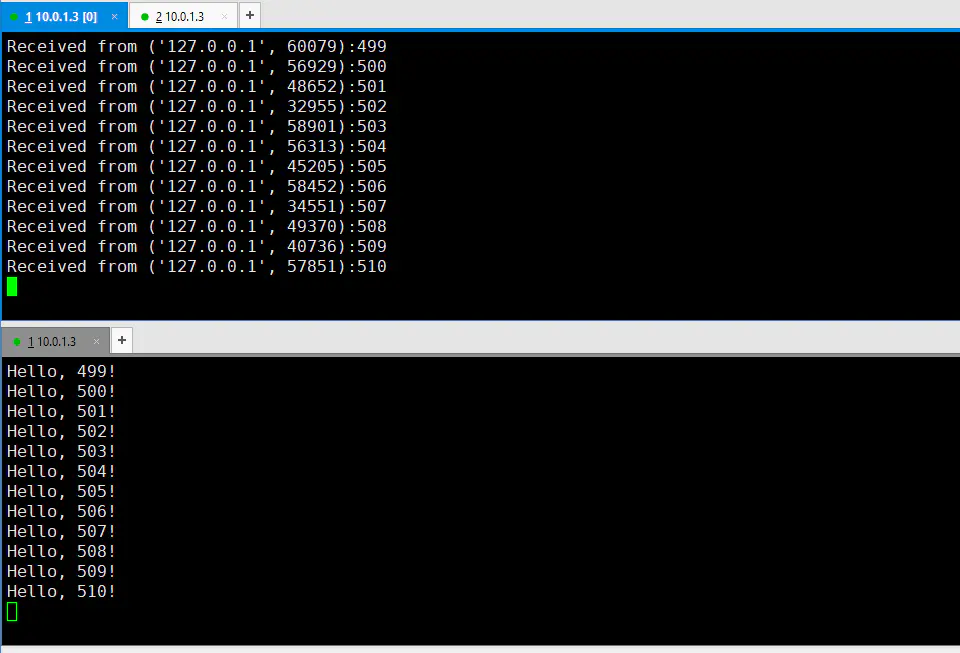
由图可知只成功了511个。
查看文档得知listen指令有个backlog参数,此参数在Linux系统中默认为511:

悲剧的是backlog参数和udp参数不能同时使用。
Linux系统编写Systemd Service实践
Linux系统编写Systemd Service实践
Systemd 服务是一种以 .service 结尾的单元(unit)配置文件,用于控制由Systemd 控制或监视的进程。简单说,用于后台以守护精灵(daemon)的形式运行程序。Systemd 广泛应用于新版本的RHEL、SUSE Linux Enterprise、CentOS、Fedora和openSUSE中,用于替代旧有的服务管理器service。

开始
Systemd 服务的内容主要分为三个部分,控制单元(unit)的定义、服务(service)的定义、以及安装部分。服务的路径位于/etc/systemd/system目录(系统的服务位于/usr/lib/systemd/system),以 .service 结尾的单元(unit)配置文件,这篇文章以创建nginx service为例,这里假设您已经自行编译安装好了nginx,下面我们来创建一个nginx service
#创建一个nginx.service文件
vi /etc/systemd/system/nginx.service
内容如下:
[Unit]
Description=Nginx - high performance web server
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/nginx/sbin/nginx
ExecReload=/usr/local/nginx/sbin/nginx -s reload
ExecStop=/usr/local/nginx/sbin/nginx -s stop
[Install]
WantedBy=multi-user.target
输入命令systemctl daemon-reload来加载刚刚创建的nginx服务,这样我们就可以用Systemd的方式来管理nginx了,命令如下:
#启动nginx
systemctl start nginx
#重载nginx
systemctl reload nginx
#停止nginx
systemctl stop nginx
#重启nginx
systemctl restart nginx
#如果需要开机启动
systemctl enable nginx
#如果需要取消开机启动
systemctl disable nginx
定义控制单元 [Unit]
从上面的例子中我们看到Unit内容如下:
[Unit]
Description=Nginx - high performance web server
After=network.target
- Description:代表整个单元的描述,可根据需要任意填写。
- Before/After:指定启动顺序。
- network.target代表有网路,network-online.target代表一个连通着的网络。
定义服务本体 [service]
上面的Service中服务本体内容为:
[Service]
Type=forking
ExecStart=/usr/local/nginx/sbin/nginx
ExecReload=/usr/local/nginx/sbin/nginx -s reload
ExecStop=/usr/local/nginx/sbin/nginx -s stop
-
Type:服务的类型,各种类型的区别如下所示
- simple:默认,这是最简单的服务类型。意思就是说启动的程序就是主体程序,这个程序要是退出那么一切皆休。
- forking:标准 Unix Daemon 使用的启动方式。启动程序后会调用 fork() 函数,把必要的通信频道都设置好之后父进程退出,留下守护精灵的子进程。
- oneshot:适用于那些被一次性执行的任务或者命令,它运行完成后便了无痕迹。因为这类服务运行完就没有任何痕迹,我们经常会需要使用 RemainAfterExit=yes。意思是说,即使没有进程存在,Systemd 也认为该服务启动成功了。同时只有这种类型支持多条命令,命令之间用;分割,如需换行可以用\。
- dbus:这个程序启动时需要获取一块 DBus 空间,所以需要和 BusName= 一起用。只有它成功获得了 DBus 空间,依赖它的程序才会被启动。
-
ExecStart:在输入的命令是start时候执行的命令,这里的命令启动的程序必须使用绝对路径,比如你必须用/sbin/arp而不能简单的以环境变量直接使用arp。
-
ExecStop:在输入的命令是stop时候执行的命令,要求同上。
-
ExecReload:这个不是必需,如果不写则你的service就不支持restart命令。ExecStart和ExecStop是必须要有的。
其实服务本体中还有更多的参数,这里在额外列举一些常用的参数:
- User:指定用户运行
- Group:指定用户组运行
- WorkingDirectory:进程工作目录,也就是说在执行前会先切换到这个目录
安装服务 [install]
上面例子中安装服务内容为:
[Install]
WantedBy=multi-user.target
- WantedBy:设置服务被谁装载,一般设置为multi-user.target
总结
Systemd Service 是一种替代/etc/init.d/下脚本的更好方式,它可以灵活的控制你什么时候要启动服务,一般情况下也不会造成系统无法启动进入紧急模式。所以如果想设置一些开机启动的东西,可以试着写 Systemd Service。当然了,前提是你使用的Linux发行版是支持它的才行。
Linux安装rinetd实现TCP/UDP端口转发
Linux安装rinetd实现TCP/UDP端口转发
在Linux系统中大多数情况选择用iptables来实现端口转发,iptables虽然强大,但配置不便,而且新手容易出错。在此分享另一个TCP/UDP端口转发工具rinetd,rinetd体积小巧,配置也很简单。
安装rinetd
这篇文章以CentOS 7为例,复制下面的命令输入,一行一个:
#安装依赖
yum -y install gcc gcc-c++ make
#下载rinetd
wget https://github.com/samhocevar/rinetd/releases/download/v0.70/rinetd-0.70.tar.gz
#解压
tar -zxvf rinetd-0.70.tar.gz
#进入目录
cd rinetd-0.70
#编译安装
./bootstrap
./configure
make && make install
安装后,可以输入rinetd -v查看当前版本。
[root@kryptcn2 rinetd-0.70]# rinetd -v
rinetd 0.70
随着时间推移,上面下载地址不一定是最新的,大家可前往Github:https://github.com/samhocevar/rinetd/releases下载最新版本。
设置TCP端口转发
#新建rinetd配置文件
vi /etc/rinetd.conf
#填写如下内容
0.0.0.0 2018 103.74.192.160 2019
#启动rinetd
rinetd -c /etc/rinetd.conf
rinetd配置文件的格式如下:
0.0.0.0:源IP2018:源端口103.74.192.160:目标IP2019:目标端口
上面配置的意思是将本地2018端口转发到103.74.192.160的2019端口,启动后可以输入netstat -apn|grep 'rinetd'查看是否运行正常,注意还需要在自己服务器防火墙放行对应的源端口,否则无法正常使用用。
从0.70版本开始rinetd已经支持UDP转发,写法如下:
127.0.0.1 8000/udp 192.168.1.2 8000/udp
创建systemd服务
为了方便管理,我们可以为rinetd编写一个systemd服务,有兴趣的同学可参考《Linux系统编写Systemd Service实践》,xiaoz已经编写好了,直接复制下面的内容即可:
#创建rinetd服务
vi /etc/systemd/system/rinetd.service
复制下面的内容进行保存:
[Unit]
Description=rinetd
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/sbin/rinetd -c /etc/rinetd.conf
[Install]
WantedBy=multi-user.target
输入命令:systemctl daemon-reload重载daemon使其生效,然后就可以使用下面的命令来管理rinetd了。
#启动rinetd
systemctl start rinetd
#设置开机启动
systemctl enable rinetd
#停止rinetd
systemctl stop rinetd
#重启
systemctl restart rinetd
rinetd的一些问题
rinetd支持转发到域名,rinetd会提前解析域名,并将解析出的IP缓存到内存中,如果您的域名解析IP发生了变化必须重启rinetd才会生效,所以rinetd并不适合转发到域名IP经常发生变化的情况,而socat则不存在此问题。
其它转发工具
总结
rinetd安装和配置都非常简单,并且从0.70版本开始已经支持UDP转发,但rinetd具体性能如何xiaoz并未进一步测试,不知道高并发的情况下能否扛得住。
使用Nginx进行TCP/UDP端口转发
使用Nginx进行TCP/UDP端口转发
Nginx (engine x) 是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP服务器。在1.9.13版本后,Nginx已经支持端口转发。之前分享过《Linux安装rinetd实现TCP端口转发》,rinetd配置简单,使用方便,但遗憾的是不支持UDP转发。如果需要同时支持TCP/UDP端口转发可以使用Nginx
安装Nginx
可以自行去官方http://nginx.org/下载最新版本Nginx编译安装,注意版本一定要大于1.9.1,编译的时候需要--with-stream这个模块支持。
编译方法这里就不介绍了,这篇文章直接使用xiaoz写好的一键脚本安装Nginx,省时、省力,直接执行下面的命令即可。
#执行下面的命令,根据提示完成安装
wget https://raw.githubusercontent.com/helloxz/nginx-cdn/master/nginx.sh && bash nginx.sh
#安装完成后执行下面的命令让环境变量生效
source /etc/profile
#执行下面的命令查看nginx信息
nginx -V

端口转发
在nginx.conf添加如下配置,并使用nginx -s reload重载nginx使其生效,同时注意防火墙/安全组放行对应的端口。
stream {
#将12345端口转发到192.168.1.23的3306端口
server {
listen 12345;
proxy_connect_timeout 5s;
proxy_timeout 20s;
proxy_pass 192.168.1.23:3306;
}
#将udp 53端口转发到192.168.1.23 53端口
server {
listen 53 udp reuseport;
proxy_timeout 20s;
proxy_pass 192.168.1.23:53;
}
#ipv4转发到ipv6
server {
listen 9135;
proxy_connect_timeout 10s;
proxy_timeout 30s;
proxy_pass [2607:fcd0:107:3cc::1]:9135;
}
}
- listen:后面填写源端口(也就是当前服务器端口),默认协议为TCP,可以指定为UDP协议
- proxy_connect_timeout:连接超时时间
- proxy_timeout:超时时间
- proxy_pass:填写转发目标的IP及端口号
注意:nginx可以将IPV4的数据包转发到IPV6,IPV6的IP需要使用[]括起来。
总结
目前能实现端口转发的工具大致有:rinetd、SSH、iptables、nginx、haproxy,其中rinetd配置最为简单,但不支持UDP转发,并且该软件已经好几年未更新,如果您服务器上已经安装了nginx,不妨用nginx做端口转发。
此文部分内容参考了:
其它nginx相关文章
linux系统中rsync+inotify实现服务器之间文件实时同步
linux系统中rsync+inotify实现服务器之间文件实时同步
- rsync
与传统的cp、tar备份方式相比,rsync具有安全性高、备份迅速、支持增量备份等优点,通过rsync可以解决对实时性要求不高的数据备份需求,例如定期的备份文件服务器数据到远端服务器,对本地磁盘定期做数据镜像等。 随着应用系统规模的不断扩大,对数据的安全性和可靠性也提出的更好的要求,rsync在高端业务系统中也逐渐暴露出了很多不足,首先,rsync同步数据时,需要扫描所有文件后进行比对,进行差量传输。如果文件数量达到了百万甚至千万量级,扫描所有文件将是非常耗时的。而且正在发生变化的往往是其中很少的一部分,这是非常低效的方式。其次,rsync不能实时的去监测、同步数据,虽然它可以通过linux守护进程的方式进行触发同步,但是两次触发动作一定会有时间差,这样就导致了服务端和客户端数据可能出现不一致,无法在应用故障时完全的恢复数据。基于以上原因,rsync+inotify组合出现了!
1. rsync ---- remote synchronize ,是一款实现远程同步功能的软件;
2. rsync使用“Rsync算法”来同步文件,该算法只传送两个文件的不同部分,因此速度相当快;
3. 同步文件的同时,可以保持原来文件的权限、时间 和目录结构;
4. 对于多个文件来说,内部流水线减少文件等待的延时;
5. rsync默认监听TCP 873端口,通过远程shell如rsh和ssh复制文件。同时要求必须在远程和本地系统上都安装sync.
- inotify
Inotify 是一种强大的、细粒度的、异步的文件系统事件监控机制,linux内核从2.6.13起,加入了Inotify支持,通过Inotify可以监控文件系统中添加、删除,修改、移动等各种细微事件,利用这个内核接口,第三方软件就可以监控文件系统下文件的各种变化情况,而 inotify-tools 就是这样的一个第三方软件。
在上面章节中,我们讲到,rsync可以实现触发式的文件同步,但是通过 crontab 守护进程方式进行触发,同步的数据和实际数据会有差异,而inotify可以监控文件系统的各种变化,当文件有任何变动时,就触发rsync同步,这样刚好解决了同步数据的实时性问题。
具体大家可以参照http://www.ibm.com/developerworks/cn/linux/l-ubuntu-inotify/index.html来进行学习。
接下面我们来开始进行rsync与inotify的安装、配置、测试。
下面是2个服务器的结构,分别为主机名、ip、同步的目录,并将2台服务器均是CentOS 6.5发行版本。
| Host | IP | Docoment |
|---|---|---|
| Server | 192.168.1.21 | /tmp |
| Client | 192.168.1.22 | /tmp |
主服务器(Server)
其中主服务器需要安装rsync与inotify,主服务器作为server,向备份服务器client传输文件
1、安装rsync
该版本的已安装rsync,如果没有,可使用yum安装(也可以使用源码安装,这里就不多做介绍了):
#安装rsync和xinetd,并创建目录:
yum install rsync xinetd
#配置xinetd:
vi /etc/xinetd.d/rsync
#disable = yes修改为
disable = no
启动xinetd服务:
service xinetd start
2、建立密码认证文件
代码如下:
[root@Server ]# echo "rsync-pwd" >/etc/rsync.passwd
#其中rsync-pwd可以自己设置密码,rsync.passwd名字也可以自己设置
[root@Server]# chmod 600 /etc/rsync.passwd
#无论是为了安全,还是为了避免出现以下错误,密码文件都需要给600权限
- 配置 Rsync
- 配置文件
rsync的主要有以下三个配置文件:
rsyncd.conf ----主配置文件,需要手动生成
rsyncd.secrets ----密码文件
rsyncd.motd ----rysnc服务器信息
3、安装inotify
[root@Server]# cd /usr/src/
[root@Server src]# wget http://cloud.github.com/downloads/rvoicilas/inotify-tools/inotify-tools-3.14.tar.gz
[root@Server src]# tar zxvf inotify-tools-3.14.tar.gz
[root@Server src]# cd inotify-tools-3.14
[root@Server inotify-tools-3.14]# ./configure --prefix=/usr/local/inotify
[root@Server inotify-tools-3.14]# make
[root@Server inotify-tools-3.14]# make install
4、创建rsync复制脚本
此项功能主要是将server端的目录/tmp里的内容,如果修改了(无论是添加、修改、删除文件)能够通过inotify监控到,并通过rsync实时的同步给client的/tmp里,下面是通过shell脚本实现的。
#!/bin/bash
host=192.168.1.22
src=/tmp/
des=web
user=webuser
/usr/local/inotify/bin/inotifywait -mrq --timefmt '%d/%m/%y %H:%M' --format '%T %w%f%e' -e modify,delete,create,attrib $src \
| while read files
do
/usr/bin/rsync -vzrtopg --delete --progress --password-file=/usr/local/rsync/rsync.passwd $src $user@$host::$des
echo "${files} was rsynced" >>/tmp/rsync.log 2>&1
done
注意:建议各位吧rsync的日志放到其他的目录下(非备份目录)。 其中host是client的ip,src是server端要实时监控的目录,des是认证的模块名,需要与client一致,user是建立密码文件里的认证用户。 把这个脚本命名为rsync.sh,放到监控的目录里,比如我的就放到/tmp下面,并给予764权限
[root@Server tmp]# chmod 764 rsync.sh
然后运行这个脚本
[root@Server tmp]# sh /tmp/rsync.sh &
请记住,只有在备份服务器client端的rsync安装并启动rsync之后,在启动rsync.sh脚本,否则有时候会满屏出现:
rsync: failed to connect to 192.168.1.22: Connection refused (111)
rsync error: error in socket IO (code 10) at clientserver.c(107) [sender=2.6.8]
我们还可以把rsync.sh脚本加入到开机启动项里
[root@Server tmp]# echo "/tmp/rsync.sh" >> /etc/rc.local
备份服务器(Client)
1、安装rsync(备份服务器只安装rsync)
#安装rsync和xinetd,并创建目录:
yum install rsync xinetd
#配置xinetd:
vi /etc/xinetd.d/rsync
#disable = yes修改为
disable = no
启动xinetd服务:
service xinetd start
2、建立用户与密码认证文件
[root@Client]# echo "webuser:rsync-pwd" > /etc/rsync.passwd
#请记住,在server端建立的密码文件,只有密码,没有用户名;而在备份服务端client里建立的密码文件,用户名与密码都有。
[root@Client]# chmod 600 /etc/rsync.passwd
#需要给密码文件600权限
3、建立rsync配置文件
vim /etc/rsyncd.conf
uid = root
gid = root
use chroot = no
max connections = 10
strict modes = yes
pid file = /var/run/rsyncd.pid
lock file = /var/run/rsync.lock
log file = /var/log/rsyncd.log
[web]
path = /tmp/
comment = web file
ignore errors
read only = no
write only = no
hosts allow = 192.168.10.220
hosts deny = *
list = false
uid = root
gid = root
auth users = webuser
secrets file = /usr/local/rsync/rsync.passwd
其中web是server服务端里的认证模块名称,需要与主服务器里的一致,以上的配置我的自己服务器里的配置,以供参考。
4、启动rsync
service xinetd start
chkconfig xinetd on #设置开机自启动
测试
现在rsync与inotify在server端安装完成,rsync在备份服务器client端也安装完成。接下来就可以来测试一下:
在server里创建个test-rsync文件,看看client是否能收到
[root@Server tmp]# touch test-rsync
再看client端是否有test-rsync文件,同时client端的tmp目录文件是否与server端的文件完全一致。如果一致,则表示已经设置成功。
附
配置文件详细说明:
注释:
uid = nobody
进行同步或者备份的用户,nobody 为任何用户
gid = nobody
进行备份的组,nobody为任意组
use chroot = no
如果"use chroot"指定为true,那么rsync在传输文件以前首先chroot到path参数所指定的目录下。这样做的原因是实现额外的安全防护,但是缺点是需要以root权限,并且不能备份指向外部的符号连接所指向的目录文件。默认情况下chroot值为true.但是一般不需要,选择no或false
list = no
不允许列清单
max connections = 10
最大连接数
timeout = 600
覆盖客户指定的IP超时时间,也就是说rsync服务器不会永远等待一个崩溃的客户端。
pidfile = /var/run/rsyncd.pid
pid文件的存放位置
lock file = /var/run/rsync.lock
锁文件的存放位置
log file = /var/log/rsyncd.log
日志文件的存放位置
[data]
这里是认证模块名,即跟samba语法一样,是对外公布的名字
path = /home/backup
这里是参与同步的目录
ignore errors
可以忽略一些无关的IO错误
read only = no
允许可读可写
list = no
不允许列清单
hosts allow = 192.168.1.0/255.255.255.0
这里可以指定单个IP,也可以指定整个网段,能提高安全性。格式是ip 与ip 之间、ip和网段之间、网段和网段之间要用空格隔开
auth users = test
认证的用户名
secrets file = /etc/rsyncd.password
密码文件存放地址
注意:
1、[backup] 认证模块名和 path = /www/backup/ 参与同步的目录
这里的path 大家要记好了,这里不要随便的一设置就直接完事,要知道这里是认证模块的,以后从客户机备份的数据会存储在这里。
2、auth users = redhat 认证的用户名 这个名字是服务器端实实在在存在用户,大家不要直接跟步骤走却忽略了这点。如果服务器端少了这个的话我估计你的数据同步就实现不了,大家要谨记。
rsync 用法教程
rsync 用法教程
简介
rsync 是一个常用的 Linux 应用程序,用于文件同步。
它可以在本地计算机与远程计算机之间,或者两个本地目录之间同步文件(但不支持两台远程计算机之间的同步)。它也可以当作文件复制工具,替代 cp 和 mv 命令。
它名称里面的 r 指的是 remote,rsync 其实就是"远程同步"(remote sync)的意思。与其他文件传输工具(如 FTP 或 scp)不同,rsync 的最大特点是会检查发送方和接收方已有的文件,仅传输有变动的部分(默认规则是文件大小或修改时间有变动)。
安装
如果本机或者远程计算机没有安装 rsync,可以用下面的命令安装。
# Debian
$ sudo apt-get install rsync
# Red Hat
$ sudo yum install rsync
# Arch Linux
$ sudo pacman -S rsync
注意,传输的双方都必须安装 rsync。
基本用法
-r 参数
本机使用 rsync 命令时,可以作为 cp 和 mv 命令的替代方法,将源目录同步到目标目录。
$ rsync -r source destination
上面命令中, -r 表示递归,即包含子目录。注意, -r 是必须的,否则 rsync 运行不会成功。 source 目录表示源目录, destination 表示目标目录。
如果有多个文件或目录需要同步,可以写成下面这样。
$ rsync -r source1 source2 destination
上面命令中, source1 、 source2 都会被同步到 destination 目录。
-a 参数
-a 参数可以替代 -r ,除了可以递归同步以外,还可以同步元信息(比如修改时间、权限等)。由于 rsync 默认使用文件大小和修改时间决定文件是否需要更新,所以 -a 比 -r 更有用。下面的用法才是常见的写法。
$ rsync -a source destination
目标目录 destination 如果不存在,rsync 会自动创建。执行上面的命令后,源目录 source 被完整地复制到了目标目录 destination 下面,即形成了 destination/source 的目录结构。
如果只想同步源目录 source 里面的内容到目标目录 destination ,则需要在源目录后面加上斜杠。
$ rsync -a source/ destination
上面命令执行后, source 目录里面的内容,就都被复制到了 destination 目录里面,并不会在 destination 下面创建一个 source 子目录。
-n 参数
如果不确定 rsync 执行后会产生什么结果,可以先用 -n 或 --dry-run 参数模拟执行的结果。
$ rsync -anv source/ destination
上面命令中, -n 参数模拟命令执行的结果,并不真的执行命令。 -v 参数则是将结果输出到终端,这样就可以看到哪些内容会被同步。
--delete 参数
默认情况下,rsync 只确保源目录的所有内容(明确排除的文件除外)都复制到目标目录。它不会使两个目录保持相同,并且不会删除文件。如果要使得目标目录成为源目录的镜像副本,则必须使用 --delete 参数,这将删除只存在于目标目录、不存在于源目录的文件。
$ rsync -av --delete source/ destination
上面命令中, --delete 参数会使得 destination 成为 source 的一个镜像。
排除文件
--exclude 参数
有时,我们希望同步时排除某些文件或目录,这时可以用 --exclude 参数指定排除模式。
$ rsync -av --exclude='*.txt' source/ destination
# 或者
$ rsync -av --exclude '*.txt' source/ destination
上面命令排除了所有 TXT 文件。
注意,rsync 会同步以"点"开头的隐藏文件,如果要排除隐藏文件,可以这样写 --exclude=".*" 。
如果要排除某个目录里面的所有文件,但不希望排除目录本身,可以写成下面这样。
$ rsync -av --exclude 'dir1/*' source/ destination
多个排除模式,可以用多个 --exclude 参数。
$ rsync -av --exclude 'file1.txt' --exclude 'dir1/*' source/ destination
多个排除模式也可以利用 Bash 的大扩号的扩展功能,只用一个 --exclude 参数。
$ rsync -av --exclude={'file1.txt','dir1/*'} source/ destination
如果排除模式很多,可以将它们写入一个文件,每个模式一行,然后用 --exclude-from 参数指定这个文件。
$ rsync -av --exclude-from='exclude-file.txt' source/ destination
--include 参数
--include 参数用来指定必须同步的文件模式,往往与 --exclude 结合使用。
$ rsync -av --include="*.txt" --exclude='*' source/ destination
上面命令指定同步时,排除所有文件,但是会包括 TXT 文件。
远程同步
SSH 协议
rsync 除了支持本地两个目录之间的同步,也支持远程同步。它可以将本地内容,同步到远程服务器。
$ rsync -av source/ username@remote_host:destination
也可以将远程内容同步到本地。
$ rsync -av username@remote_host:source/ destination
rsync 默认使用 SSH 进行远程登录和数据传输。
由于早期 rsync 不使用 SSH 协议,需要用 -e 参数指定协议,后来才改的。所以,下面 -e ssh 可以省略。
$ rsync -av -e ssh source/ user@remote_host:/destination
但是,如果 ssh 命令有附加的参数,则必须使用 -e 参数指定所要执行的 SSH 命令。
$ rsync -av -e 'ssh -p 2234' source/ user@remote_host:/destination
上面命令中,-e参数指定 SSH 使用2234端口。
rsync 协议
除了使用 SSH,如果另一台服务器安装并运行了 rsync 守护程序,则也可以用 rsync:// 协议(默认端口873)进行传输。具体写法是服务器与目标目录之间使用双冒号分隔 :: 。
$ rsync -av source/ 192.168.122.32::module/destination
注意,上面地址中的 module 并不是实际路径名,而是 rsync 守护程序指定的一个资源名,由管理员分配。
如果想知道 rsync 守护程序分配的所有 module 列表,可以执行下面命令。
$ rsync rsync://192.168.122.32
rsync 协议除了使用双冒号,也可以直接用 rsync:// 协议指定地址。
$ rsync -av source/ rsync://192.168.122.32/module/destination
增量备份
rsync 的最大特点就是它可以完成增量备份,也就是默认只复制有变动的文件。
除了源目录与目标目录直接比较,rsync 还支持使用基准目录,即将源目录与基准目录之间变动的部分,同步到目标目录。
具体做法是,第一次同步是全量备份,所有文件在基准目录里面同步一份。以后每一次同步都是增量备份,只同步源目录与基准目录之间有变动的部分,将这部分保存在一个新的目标目录。这个新的目标目录之中,也是包含所有文件,但实际上,只有那些变动过的文件是存在于该目录,其他没有变动的文件都是指向基准目录文件的硬链接。
--link-dest 参数用来指定同步时的基准目录。
$ rsync -a --delete --link-dest /compare/path /source/path /target/path
上面命令中,--link-dest 参数指定基准目录 /compare/path ,然后源目录 /source/path 跟基准目录进行比较,找出变动的文件,将它们拷贝到目标目录 /target/path 。那些没变动的文件则会生成硬链接。这个命令的第一次备份时是全量备份,后面就都是增量备份了。
下面是一个脚本示例,备份用户的主目录。
#!/bin/bash
# A script to perform incremental backups using rsync
set -o errexit
set -o nounset
set -o pipefail
readonly SOURCE_DIR="${HOME}"
readonly BACKUP_DIR="/mnt/data/backups"
readonly DATETIME="$(date '+%Y-%m-%d_%H:%M:%S')"
readonly BACKUP_PATH="${BACKUP_DIR}/${DATETIME}"
readonly LATEST_LINK="${BACKUP_DIR}/latest"
mkdir -p "${BACKUP_DIR}"
rsync -av --delete \
"${SOURCE_DIR}/" \
--link-dest "${LATEST_LINK}" \
--exclude=".cache" \
"${BACKUP_PATH}"
rm -rf "${LATEST_LINK}"
ln -s "${BACKUP_PATH}" "${LATEST_LINK}"
上面脚本中,每一次同步都会生成一个新目录 ${BACKUP_DIR}/${DATETIME} ,并将软链接 ${BACKUP_DIR}/latest 指向这个目录。下一次备份时,就将 ${BACKUP_DIR}/latest 作为基准目录,生成新的备份目录。最后,再将软链接 ${BACKUP_DIR}/latest 指向新的备份目录。
配置项
-a 、 --archive 参数表示存档模式,保存所有的元数据,比如修改时间(modification time)、权限、所有者等,并且软链接也会同步过去。
--append 参数指定文件接着上次中断的地方,继续传输。
--append-verify 参数跟 --append 参数类似,但会对传输完成后的文件进行一次校验。如果校验失败,将重新发送整个文件。
-b 、--backup 参数指定在删除或更新目标目录已经存在的文件时,将该文件更名后进行备份,默认行为是删除。更名规则是添加由 --suffix 参数指定的文件后缀名,默认是~。
--backup-dir 参数指定文件备份时存放的目录,比如 --backup-dir=/path/to/backups 。
--bwlimit 参数指定带宽限制,默认单位是 KB/s ,比如 --bwlimit=100 。
-c 、 --checksum 参数改变 rsync 的校验方式。默认情况下,rsync 只检查文件的大小和最后修改日期是否发生变化,如果发生变化,就重新传输;使用这个参数以后,则通过判断文件内容的校验和,决定是否重新传输。
--delete 参数删除只存在于目标目录、不存在于源目标的文件,即保证目标目录是源目标的镜像。
-e 参数指定使用 SSH 协议传输数据。
--exclude 参数指定排除不进行同步的文件,比如 --exclude="*.iso" 。
--exclude-from 参数指定一个本地文件,里面是需要排除的文件模式,每个模式一行。
--existing 、 --ignore-non-existing 参数表示不同步目标目录中不存在的文件和目录。
-h 参数表示以人类可读的格式输出。
-h 、--help 参数返回帮助信息。
-i 参数表示输出源目录与目标目录之间文件差异的详细情况。
--ignore-existing 参数表示只要该文件在目标目录中已经存在,就跳过去,不再同步这些文件。
--include 参数指定同步时要包括的文件,一般与 --exclude 结合使用。
--link-dest 参数指定增量备份的基准目录。
-m 参数指定不同步空目录。
--max-size 参数设置传输的最大文件的大小限制,比如不超过 200KB(--max-size='200k')。
--min-size 参数设置传输的最小文件的大小限制,比如不小于 10KB(--min-size=10k)。
-n 参数或 --dry-run 参数模拟将要执行的操作,而并不真的执行。配合 -v 参数使用,可以看到哪些内容会被同步过去。
-P 参数是 --progress 和 --partial 这两个参数的结合。
--partial 参数允许恢复中断的传输。不使用该参数时, rsync 会删除传输到一半被打断的文件;使用该参数后,传输到一半的文件也会同步到目标目录,下次同步时再恢复中断的传输。一般需要与 --append 或 --append-verify 配合使用。
--partial-dir 参数指定将传输到一半的文件保存到一个临时目录,比如 --partial-dir=.rsync-partial 。一般需要与 --append 或 --append-verify 配合使用。
--progress 参数表示显示进展。
-r 参数表示递归,即包含子目录。
--remove-source-files 参数表示传输成功后,删除发送方的文件。
--size-only 参数表示只同步大小有变化的文件,不考虑文件修改时间的差异。
--suffix 参数指定文件名备份时,对文件名添加的后缀,默认是 ~ 。
-u 、 --update 参数表示同步时跳过目标目录中修改时间更新的文件,即不同步这些有更新的时间戳的文件。
-v 参数表示输出细节。 -vv 表示输出更详细的信息, -vvv 表示输出最详细的信息。
--version 参数返回 rsync 的版本。
-z参数指定同步时压缩数据。
参考链接
How To Use Rsync to Sync Local and Remote Directories on a VPS, Justin Ellingwood
Mirror Your Web Site With rsync, Falko Timme
Examples on how to use Rsync, Egidio Docile
How to create incremental backups using rsync on Linux, Egidio Docile
(完)
Centos 6无法使用yum解决办法(centos6停止更新)
Centos 6无法使用yum解决办法(centos6停止更新)
12月后Centos 6 系统无法使用yum出现错误
相信已经有一部分朋友今天连接到CentOS 6的服务器后执行yum后发现报错,那么发生了什么?
CentOS 6已经随着2020年11月的结束进入了EOL(Reaches End of Life),不过有一些老设备依然需要支持,CentOS官方也给这些还不想把CentOS 6扔进垃圾堆的用户保留了最后一个版本的镜像,只是这个镜像不会再有更新了
官方便在12月2日正式将CentOS 6相关的软件源移出了官方源,随之而来逐级镜像也会陆续将其删除。
不过有一些老设备依然需要维持在当前系统,CentOS官方也给这些还不想把CentOS 6扔进垃圾堆的用户保留了各个版本软件源的镜像,只是这个软件源不会再有更新了。
一键修复
sed -i "s|enabled=1|enabled=0|g" /etc/yum/pluginconf.d/fastestmirror.conf
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
curl -o /etc/yum.repos.d/CentOS-Base.repo https://www.xmpan.com/Centos-6-Vault-Aliyun.repo
yum clean all
yum makecache
手动修复教程:
首先把fastestmirrors关了
#编辑
vi /etc/yum/pluginconf.d/fastestmirror.conf
#修改
enable=0
#或者执行以下命令
sed -i "s|enabled=1|enabled=0|g" /etc/yum/pluginconf.d/fastestmirror.conf
先把之前的repo挪到备份,然后下面两个二选一
- 备份
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak
- 替换为官方Vault源(海外服务器用)
curl -o /etc/yum.repos.d/CentOS-Base.repo https://www.xmpan.com/Centos-6-Vault-Official.repo
或者替换为阿里云Vault镜像(国内服务器用)
curl -o /etc/yum.repos.d/CentOS-Base.repo https://www.xmpan.com/Centos-6-Vault-Aliyun.repo
Nginx配置中不同请求匹配不同请求
Nginx配置中不同请求匹配不同请求
一、正则匹配
- ~ 为区分大小写匹配
- ~* 为不区分大小写匹配
- !和!*分别为区分大小写不匹配及不区分大小写不匹配
二、文件及目录匹配
- -f和!-f用来判断是否存在文件
- -d和!-d用来判断是否存在目录
- -e和!-e用来判断是否存在文件或目录
- -x和!-x用来判断文件是否可执行
三.rewrite指令的最后一项参数为flag标记,flag标记有:
- last 相当于apache里面的[L]标记,表示rewrite。
- break本条规则匹配完成后,终止匹配,不再匹配后面的规则。
- redirect 返回302临时重定向,浏览器地址会显示跳转后的URL地址。
- permanent 返回301永久重定向,浏览器地址会显示跳转后的URL地址。
使用last和break实现URI重写,浏览器地址栏不变。而且两者有细微差别,使用alias指令必须用last标记;使用proxy_pass指令时,需要使用break标记。Last标记在本条rewrite规则执行完毕后,会对其所在server{…}标签重新发起请求,而break标记则在本条规则匹配完成后,终止匹配。
四.NginxRewrite 规则相关指令
1.break指令
使用环境:server,location,if;
该指令的作用是完成当前的规则集,不再处理rewrite指令。
2.if指令
使用环境:server,location
该指令用于检查一个条件是否符合,如果条件符合,则执行大括号内的语句。If指令不支持嵌套,不支持多个条件&&和||处理。
location /CMS/ {##请求以CMS开头的走此location
if ($request_uri ~ "CMS/was") { ##内容包含 CMS/was 的转发至以下请求(区分大小写)
proxy_pass http://10.1.1.247;
break; ##break表示
}
if ($request_uri ~ "CMS/Evaluate.action") { ##同上
proxy_pass http://10.1.1.247;
break;
}
rewrite ^ http://www.baidu.com/;##CMS后其余的请求统一重定向至百度
}
3.return指令
语法:returncode ;
使用环境:server,location,if;
该指令用于结束规则的执行并返回状态码给客户端。
location ~ .*\.(sh|bash)?$ {
return 403;
}
4.rewrite 指令
语法:rewriteregex replacement flag
使用环境:server,location,if
该指令根据表达式来重定向URI,或者修改字符串。指令根据配置文件中的顺序来执行。注意重写表达式只对相对路径有效。如果你想配对主机名,你应该使用if语句,示例如下:
if( $host ~* www\.(.*) ) {
set $host_without_www $1;
rewrite ^(.*)$ http://$host_without_www$1permanent;
}
5.Set指令
语法:setvariable value ; 默认值:none; 使用环境:server,location,if;
该指令用于定义一个变量,并给变量赋值。变量的值可以为文本、变量以及文本变量的联合。
set$varname "hello world";
6.Uninitialized_variable_warn指令
语法:uninitialized_variable_warnon|off
使用环境:http,server,location,if
该指令用于开启和关闭未初始化变量的警告信息,默认值为开启。
五.Nginx的Rewrite规则编写实例
1.当访问的文件和目录不存在时,重定向到某个html文件
if( !-e $request_filename )
{
rewrite ^/(.*)$ index.htmllast;
}
2.目录对换 /123456/xxxx ====> /xxxx?id=123456
rewrite ^/(\d+)/(.+)/ /$2?id=$1 last;
3.如果客户端使用的是IE浏览器,则重定向到/ie目录下
if( $http_user_agent ~ MSIE)
{
rewrite ^(.*)$ /ie/$1 break;
}
4.禁止访问多个目录
location ~ ^/(cron|templates)/
{
deny all;
break;
}
5.禁止访问以/data开头的文件
location ~ ^/data
{
deny all;
}
6.禁止访问以.sh,.flv,.mp3为文件后缀名的文件
location ~ .*\.(sh|flv|mp3)$
{
return 403;
}
7.设置某些类型文件的浏览器缓存时间
location ~ .*\.(gif|jpg|jpeg|png|bmp|swf)$
{
expires 30d;
}
location ~ .*\.(js|css)$
{
expires 1h;
}
8.给favicon.ico和robots.txt设置过期时间;
这里为favicon.ico为99天,robots.txt为7天并不记录404错误日志
location ~(favicon.ico) {
log_not_found off;
expires 99d;
break;
}
location ~(robots.txt) {
log_not_found off;
expires 7d;
break;
}
9.设定某个文件的过期时间;这里为600秒,并不记录访问日志
location ^~ /html/scripts/loadhead_1.js {
access_log off;
root /opt/lampp/htdocs/web;
expires 600;
break;
}
10.文件反盗链并设置过期时间
这里的return412 为自定义的http状态码,默认为403,方便找出正确的盗链的请求
rewrite ^/ http: //img.linuxidc.net/leech.gif;//显示一张防盗链图片
access_log off; //不记录访问日志,减轻压力
expires 3d //所有文件3天的浏览器缓存
location ~*^.+\.(jpg|jpeg|gif|png|swf|rar|zip|css|js)$ {
valid_referers none blocked *.linuxidc.com*.linuxidc.net localhost 208.97.167.194;
if ($invalid_referer) {
rewrite ^/ http://img.linuxidc.net/leech.gif;
return 412;
break;
}
access_log off;
root /opt/lampp/htdocs/web;
expires 3d;
break;
}
11.只允许固定ip访问网站,并加上密码
root /opt/htdocs/www;
allow 208.97.167.194;
allow 222.33.1.2;
allow 231.152.49.4;
deny all;
auth_basic “C1G_ADMIN”;
auth_basic_user_file htpasswd;
12.将多级目录下的文件转成一个文件,增强seo效果
/job-123-456-789.html 指向/job/123/456/789.html
rewrite^/job-([0-9]+)-([0-9]+)-([0-9]+)\.html$ /job/$1/$2/jobshow_$3.html last;
14.将根目录下某个文件夹指向2级目录
如/shanghaijob/ 指向 /area/shanghai/
如果你将last改成permanent,那么浏览器地址栏显是/location/shanghai/
rewrite ^/([0-9a-z]+)job/(.*)$ /area/$1/$2last;
上面例子有个问题是访问/shanghai时将不会匹配
rewrite ^/([0-9a-z]+)job$ /area/$1/ last;
rewrite ^/([0-9a-z]+)job/(.*)$ /area/$1/$2last;
这样/shanghai 也可以访问了,但页面中的相对链接无法使用,
如./list_1.html真实地址是/area/shanghia/list_1.html会变成/list_1.html,导至无法访问。
那我加上自动跳转也是不行咯
(-d $request_filename)它有个条件是必需为真实目录,而我的rewrite不是的,所以没有效果
if (-d $request_filename){
rewrite ^/(.*)([^/])$ http://$host/$1$2/permanent;
}
知道原因后就好办了,让我手动跳转吧
rewrite ^/([0-9a-z]+)job$ /$1job/permanent;
rewrite ^/([0-9a-z]+)job/(.*)$ /area/$1/$2last;
15.域名跳转
server{
listen 80;
server_name jump.linuxidc.com;
index index.html index.htm index.php;
root /opt/lampp/htdocs/www;
rewrite ^/ http://www.linuxidc.com/;
access_log off;
}
16.多域名转向
server_name www.linuxidc.com www.linuxidc.net;
index index.html index.htm index.php;
root /opt/lampp/htdocs;
if ($host ~ "linuxidc\.net") {
rewrite ^(.*) http://www.linuxidc.com$1permanent;
}
六.nginx全局变量
arg_PARAMETER #这个变量包含GET请求中,如果有变量PARAMETER时的值。
args #这个变量等于请求行中(GET请求)的参数,如:foo=123&bar=blahblah;
binary_remote_addr #二进制的客户地址。
body_bytes_sent #响应时送出的body字节数数量。即使连接中断,这个数据也是精确的。
content_length #请求头中的Content-length字段。
content_type #请求头中的Content-Type字段。
cookie_COOKIE #cookie COOKIE变量的值
document_root #当前请求在root指令中指定的值。
document_uri #与uri相同。
host #请求主机头字段,否则为服务器名称。
hostname #Set to themachine’s hostname as returned by gethostname
http_HEADER
is_args #如果有args参数,这个变量等于”?”,否则等于”",空值。
http_user_agent #客户端agent信息
http_cookie #客户端cookie信息
limit_rate #这个变量可以限制连接速率。
query_string #与args相同。
request_body_file #客户端请求主体信息的临时文件名。
request_method #客户端请求的动作,通常为GET或POST。
remote_addr #客户端的IP地址。
remote_port #客户端的端口。
remote_user #已经经过Auth Basic Module验证的用户名。
request_completion #如果请求结束,设置为OK. 当请求未结束或如果该请求不是请求链串的最后一个时,为空(Empty)。
request_method #GET或POST
request_filename #当前请求的文件路径,由root或alias指令与URI请求生成。
request_uri #包含请求参数的原始URI,不包含主机名,如:”/foo/bar.php?arg=baz”。不能修改。
scheme #HTTP方法(如http,https)。
server_protocol #请求使用的协议,通常是HTTP/1.0或HTTP/1.1。
server_addr #服务器地址,在完成一次系统调用后可以确定这个值。
server_name #服务器名称。
server_port #请求到达服务器的端口号。
七.Apache和Nginx规则的对应关系
Apache的RewriteCond对应Nginx的if
Apache的RewriteRule对应Nginx的rewrite
Apache的[R]对应Nginx的redirect
Apache的[P]对应Nginx的last
Apache的[R,L]对应Nginx的redirect
Apache的[P,L]对应Nginx的last
Apache的[PT,L]对应Nginx的last
例如:允许指定的域名访问本站,其他的域名一律转向www.linuxidc.net
Apache:
RewriteCond %{HTTP_HOST} !^(.*?)\.aaa\.com$[NC]
RewriteCond %{HTTP_HOST} !^localhost$
RewriteCond %{HTTP_HOST}!^192\.168\.0\.(.*?)$
RewriteRule ^/(.*)$ http://www.linuxidc.net[R,L]
Nginx过滤示例:
if( $host ~* ^(.*)\.aaa\.com$ )
{
set $allowHost ‘1’;
}
if( $host ~* ^localhost )
{
set $allowHost ‘1’;
}
if( $host ~* ^192\.168\.1\.(.*?)$ )
{
set $allowHost ‘1’;
}
if( $allowHost !~ ‘1’ )
{
rewrite ^/(.*)$ http://www.linuxidc.netredirect ;
}
使用 flock 文件锁解决 crontab 冲突问题
使用 flock 文件锁解决 crontab 冲突问题
linux 的 crontab 命令,可以定时执行操作,最小周期是每分钟执行一次。但是如果在这一分钟之内,之前的命令并没有执行完成,就会产生冲突。接下来介绍解决冲突的办法,那就是 linux 的 flock 文件锁。
关于crontab实现每秒执行可参考《linux crontab 实现每秒执行》
格式:
flock [-sxun][-w #] fd#
flock [-sxon][-w #] file [-c] command
参数是:
-s, --shared: 获得一个共享锁
-x, --exclusive: 获得一个独占锁
-u, --unlock: 移除一个锁,通常是不需要的,脚本执行完会自动丢弃锁
-n, --nonblock: 如果没有立即获得锁,直接失败而不是等待
-w, --timeout: 如果没有立即获得锁,等待指定时间
-o, --close: 在运行命令前关闭文件的描述符号。用于如果命令产生子进程时会不受锁的管控
-c, --command: 在shell中运行一个单独的命令
-h, --help 显示帮助
-V, --version: 显示版本
继续用回第一个 test.php,文件锁使用独占锁,如果锁定则失败不等待。参数为 -xn
下面是在 crontab 中的使用:
# -xn 文件锁使用独占锁,如果锁定则失败不等待。
* * * * * flock -xn /tmp/test.lock -c 'php /home/develop/test.php >> /home/develop/test.log'
这样当任务未执行完成,下一任务判断到 /tmp/test.lock 被锁定,则结束当前的任务,下一周期再判断。
Ubuntu扩展 /dev/mapper/ubuntu--vg-ubuntu--lv空间
Ubuntu扩展 /dev/mapper/ubuntu--vg-ubuntu--lv空间
1. 查看磁盘空间
root@root:~# df -h
Filesystem Size Used Avail Use% Mounted on
udev 1.9G 0 1.9G 0% /dev
tmpfs 393M 2.1M 391M 1% /run
/dev/mapper/ubuntu--vg-ubuntu--lv 14G 4.4G 8.8G 34% /
tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/loop0 90M 90M 0 100% /snap/core/8268
/dev/sda2 976M 82M 828M 9% /boot
tmpfs 393M 20K 393M 1% /run/user/125
tmpfs 393M 56K 393M 1% /run/user/1000
查看vg
root@root:~# vgdisplay
--- Volume group ---
VG Name ubuntu-vg
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 3
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 1
Open LV 1
Max PV 0
Cur PV 1
Act PV 1
VG Size <79.00 GiB
PE Size 4.00 MiB
Total PE 20223
Alloc PE / Size 3584 / 14.00 GiB
Free PE / Size 16639 / <65.00 GiB
VG UUID mg1Zau-atla-jy56-ycyN-e6dS-UJC9-1ErQU7
扩展
lvextend -L 120G /dev/mapper/ubuntu--vg-ubuntu--lv //增大至120G
lvextend -L +20G /dev/mapper/ubuntu--vg-ubuntu--lv //增加20G
lvreduce -L 50G /dev/mapper/ubuntu--vg-ubuntu--lv //减小至50G
lvreduce -L -8G /dev/mapper/ubuntu--vg-ubuntu--lv //减小8G
lvresize -L 30G /dev/mapper/ubuntu--vg-ubuntu--lv //调整为30G
调整
resize2fs /dev/mapper/ubuntu--vg-ubuntu--lv //执行调整
搭建RTMP直播流服务器实现直播
搭建RTMP直播流服务器实现直播
服务介绍
RTMP流媒体服务器,现成的开源方案有很多,有SRS,Red5,wowoza,FMS等,我这里使用的是Nginx的rtmp插件实现实时流转发。
先在 Nginx官网 下载源码包,然后在 github 下载插件包。
为了简化安装过程,网上有很多现成的 nginx + rtmp docker 镜像。下面以 alqutami/rtmp-hls 为例来讲解 rtmp 流媒体服务器的部署。
此 Docker 映像可用于创建开箱即用的支持RTMP、HLS、DASH的视频流服务器。它还允许视频流的自适应流媒体和自定义转码。所有模块都是在 Debian 和 Alpine Linux 基础映像上从源代码构建的。
- 后端是带有nginx-rtmp-module 的 Nginx。
- FFmpeg 用于转码和自适应流媒体。
- 默认设置:
- RTMP 开启
- HLS 开启(自适应,5 个变体)
- DASH 开启
- 还提供了其他 Nginx 配置文件以允许仅 RTMP 流或无 FFmpeg 转码。
- .RTMP 流的统计页面
http://<server ip>:<server port>/stats。 - 可用的网络视频播放器(基于video.js和hls.js)位于
/usr/local/nginx/html/players.
当前图像是使用以下方法构建的:
- Nginx 1.17.5(从源代码编译)
- Nginx-rtmp-module 1.2.1(从源码编译)
- FFmpeg 4.2.1(从源代码编译)
部署服务
下载
通过 docker 方式的部署无需安装服务器依赖环境,也不用关心服务器系统发行版。主要需要安装 docker,然后执行以下命令获取镜像:
# pull rtmp-hls image
docker pull alqutami/rtmp-hls
# see rtmp-hls image
docker image ls
# save image
docker image save alqutami/rtmp-hls:latest > alqutami_rtmp-hls_latest.tar.gz
# load image
docker image load < alqutami_rtmp-hls_latest.tar.gz
安装
镜像下载安装之后,即可直接安装运行 rtmp 的 docker container
# base buid
docker run -d --name rtmp -p 1935:1935 -p 8080:8080 alqutami/rtmp-hls:latest
# see container
docker container exec -it rtmp bash
# delete container
docker container rm -f rtmp
附件:
调试
流式传输到服务器
- 将实时 RTMP 内容流式传输到:
-
rtmp://<server ip>:1935/live/<stream_key> -
<stream_key>您指定的任何流密钥在哪里。
-
- 配置 OBS 以流式传输内容:
- 转到设置 > 流式传输,选择以下设置:
- 服务:自定义流媒体服务器。
- 服务器:
rtmp://<server ip>:1935/live。 - 流密钥:您想要的任何东西,但前提是视频播放器假定流密钥是
test
查看流
-
使用 VLC:
-
转至媒体 > 打开网络流。
-
输入流 URL:
rtmp://<server ip>:1935/live/<stream-key>替换<server ip>为运行服务器的 IP,以及<stream-key>您在设置流时使用的流密钥。 -
对于 HLS 和 DASH,URL 的形式分别为:
http://<server ip>:8080/hls/<stream-key>.m3u8和http://<server ip>:8080/dash/<stream-key>_src.mpd。 -
单击播放。
-
-
使用提供的网络播放器:
-
提供的演示播放器假设调用了流密钥test并且播放器在本地主机中打开。
-
播放 RTMP 内容(需要 Flash):
http://localhost:8080/players/rtmp.html -
播放 HLS 内容:
http://localhost:8080/players/hls.html -
使用 hls.js 库播放 HLS 内容:
http://localhost:8080/players/hls_hlsjs.html -
播放 DASH 内容:
http://localhost:8080/players/dash.html -
在同一页面上播放 RTMP 和 HLS 内容:
http://localhost:8080/players/rtmp_hls.html
-
笔记:*
-
这些网络播放器被硬编码为在本地主机上播放流密钥
test。 -
更改这些播放器的流源。下载html文件,修改html文件src中video标签中的属性。然后,您可以将修改后的文件挂载到容器中,如下所示:
# conf buid
docker run -d \
--name rtmp \
-p 1935:1935 \
-p 8080:8080 \
-v /data/rtmp/nginx.conf:/etc/nginx/nginx.conf \
-v /data/rtmp/html:/usr/local/nginx/html \
alqutami/rtmp-hls:latest
# order conf copy
mkdir -p html/players
docker container cp rtmp:/usr/local/nginx/html/50x.html html/
docker container cp rtmp:/usr/local/nginx/html/index.html html/
docker container cp rtmp:/usr/local/nginx/html/players/dash.html html/players/
docker container cp rtmp:/usr/local/nginx/html/players/hls.html html/players/
docker container cp rtmp:/usr/local/nginx/html/players/hls_hlsjs.html html/players/
docker container cp rtmp:/usr/local/nginx/html/players/rtmp.html html/players/
docker container cp rtmp:/usr/local/nginx/html/players/rtmp_hls.html html/players/
docker container cp rtmp:/usr/local/nginx/html/stat.xsl html/
rtmp 保存修改后的 html 文件的目录 在哪里。
页面调试
# stat page
http://rtmp.wzhz.xyz/stat
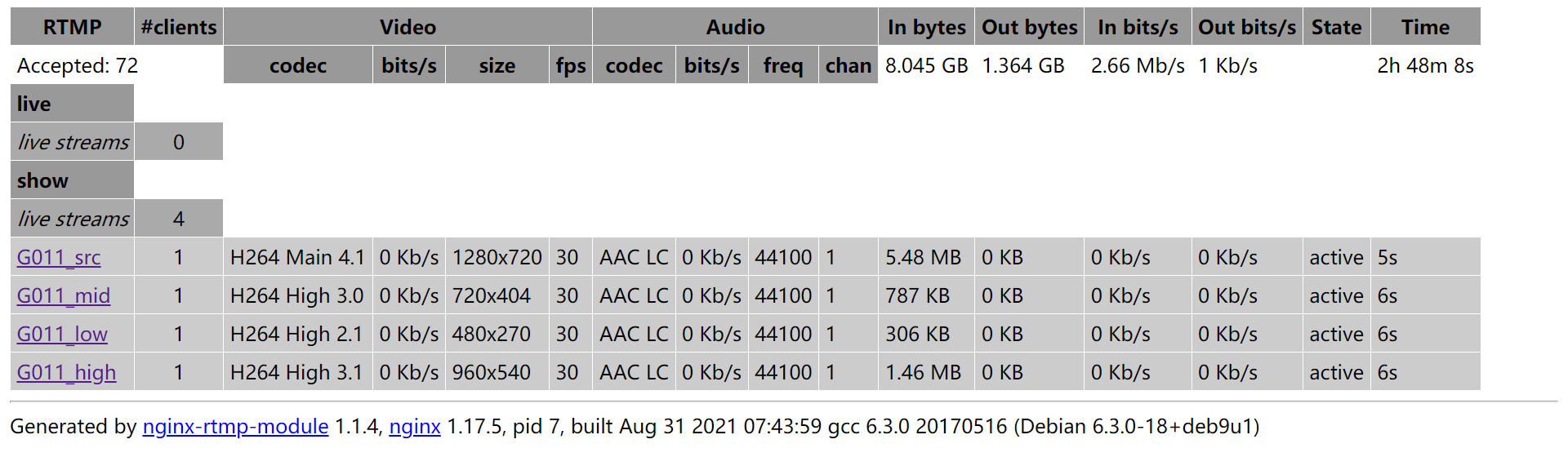
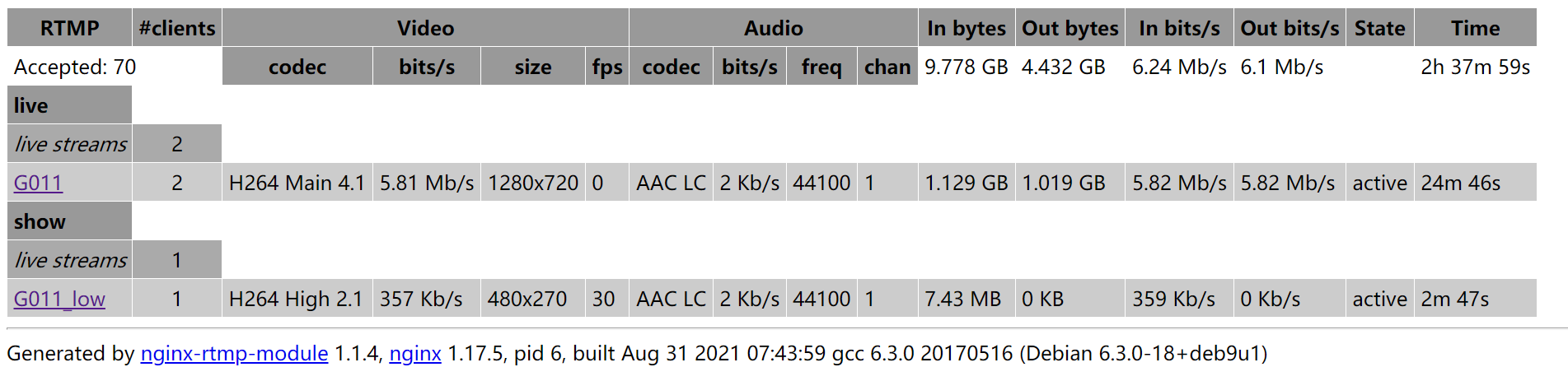
# players page
http://rtmp.wzhz.xyz/players/dash.html
http://rtmp.wzhz.xyz/players/hls.html
http://rtmp.wzhz.xyz/players/rtmp.html
http://rtmp.wzhz.xyz/players/rtmp_hls.html
http://rtmp.wzhz.xyz/players/hls_hlsjs.html

FRP使用
概览
frp 是什么?
frp 是一个专注于内网穿透的高性能的反向代理应用,支持 TCP、UDP、HTTP、HTTPS 等多种协议。可以将内网服务以安全、便捷的方式通过具有公网 IP 节点的中转暴露到公网。
为什么使用 frp?
通过在具有公网 IP 的节点上部署 frp 服务端,可以轻松地将内网服务穿透到公网,同时提供诸多专业的功能特性,这包括:
- 客户端服务端通信支持 TCP、KCP 以及 Websocket 等多种协议。
- 采用 TCP 连接流式复用,在单个连接间承载更多请求,节省连接建立时间。
- 代理组间的负载均衡。
- 端口复用,多个服务通过同一个服务端端口暴露。
- 多个原生支持的客户端插件(静态文件查看,HTTP、SOCK5 代理等),便于独立使用 frp 客户端完成某些工作。
- 高度扩展性的服务端插件系统,方便结合自身需求进行功能扩展。
- 服务端和客户端 UI 页面。
安装
关于如何安装 frp 的说明。
frp 采用 Golang 编写,支持跨平台,仅需下载对应平台的二进制文件即可执行,没有额外依赖。
系统需求
由于采用 Golang 编写,所以系统需求和最新的 Golang 对系统和平台的要求一致,具体可以参考 Golang System requirements。
下载
目前可以在 Github 的 Release 页面中下载到最新版本的客户端和服务端二进制文件,所有文件被打包在一个压缩包中。
部署
解压缩下载的压缩包,将其中的 frpc 拷贝到内网服务所在的机器上,将 frps 拷贝到具有公网 IP 的机器上,放置在任意目录。
开始使用!
编写配置文件,先通过 ./frps -c ./frps.ini 启动服务端,再通过 ./frpc -c ./frpc.ini 启动客户端。如果需要在后台长期运行,建议结合其他工具使用,例如 systemd 和 supervisor。
如果是 Windows 用户,需要在 cmd 终端中执行命令。
概念
一些概念,理解它们有助于您更好地了解和使用 frp。
原理
frp 主要由 客户端(frpc) 和 服务端(frps) 组成,服务端通常部署在具有公网 IP 的机器上,客户端通常部署在需要穿透的内网服务所在的机器上。
内网服务由于没有公网 IP,不能被非局域网内的其他用户访问。
用户通过访问服务端的 frps,由 frp 负责根据请求的端口或其他信息将请求路由到对应的内网机器,从而实现通信。
代理
在 frp 中一个代理对应一个需要暴露的内网服务。一个客户端支持同时配置多个代理。
代理类型
frp 支持多种代理类型来适配不同的使用场景。
| 类型 | 描述 |
|---|---|
| tcp | 单纯的 TCP 端口映射,服务端会根据不同的端口路由到不同的内网服务。 |
| udp | 单纯的 UDP 端口映射,服务端会根据不同的端口路由到不同的内网服务。 |
| http | 针对 HTTP 应用定制了一些额外的功能,例如修改 Host Header,增加鉴权。 |
| https | 针对 HTTPS 应用定制了一些额外的功能。 |
| stcp | 安全的 TCP 内网代理,需要在被访问者和访问者的机器上都部署 frpc,不需要在服务端暴露端口。 |
| sudp | 安全的 UDP 内网代理,需要在被访问者和访问者的机器上都部署 frpc,不需要在服务端暴露端口。 |
| xtcp | 点对点内网穿透代理,功能同 stcp,但是流量不需要经过服务器中转。 |
| tcpmux | 支持服务端 TCP 端口的多路复用,通过同一个端口访问不同的内网服务。 |
示例
这里包括多个常见的使用场景和配置示例,你可以用来亲自部署和体验这些示例。
通过 SSH 访问内网机器
这个示例通过简单配置 TCP 类型的代理让用户访问到内网的服务器。
-
在具有公网 IP 的机器上部署 frps,修改 frps.ini 文件,这里使用了最简化的配置,设置了 frp 服务器用户接收客户端连接的端口:
[common] bind_port = 7000 -
在需要被访问的内网机器上(SSH 服务通常监听在 22 端口)部署 frpc,修改 frpc.ini 文件,假设 frps 所在服务器的公网 IP 为 x.x.x.x:
[common] server_addr = x.x.x.x server_port = 7000 [ssh] type = tcp local_ip = 127.0.0.1 local_port = 22 remote_port = 6000local_ip和local_port配置为本地需要暴露到公网的服务地址和端口。remote_port表示在 frp 服务端监听的端口,访问此端口的流量将会被转发到本地服务对应的端口。 -
分别启动 frps 和 frpc。
-
通过 SSH 访问内网机器,假设用户名为 test:
ssh -oPort=6000 test@x.x.x.xfrp 会将请求
x.x.x.x:6000的流量转发到内网机器的 22 端口。
通过自定义域名访问内网的 Web 服务
这个示例通过简单配置 HTTP 类型的代理让用户访问到内网的 Web 服务。
HTTP 类型的代理相比于 TCP 类型,不仅在服务端只需要监听一个额外的端口 vhost_http_port 用于接收 HTTP 请求,还额外提供了基于 HTTP 协议的诸多功能。
-
修改 frps.ini 文件,设置监听 HTTP 请求端口为 8080:
[common] bind_port = 7000 vhost_http_port = 8080 -
修改 frpc.ini 文件,假设 frps 所在的服务器的 IP 为 x.x.x.x,
local_port为本地机器上 Web 服务监听的端口, 绑定自定义域名为custom_domains。[common] server_addr = x.x.x.x server_port = 7000 [web] type = http local_port = 80 custom_domains = www.yourdomain.com [web2] type = http local_port = 8080 custom_domains = www.yourdomain2.com -
分别启动 frps 和 frpc。
-
将
www.yourdomain.com和www.yourdomain2.com的域名 A 记录解析到 IPx.x.x.x,如果服务器已经有对应的域名,也可以将 CNAME 记录解析到服务器原先的域名。或者可以通过修改 HTTP 请求的 Host 字段来实现同样的效果。 -
通过浏览器访问
http://www.yourdomain.com:8080即可访问到处于内网机器上 80 端口的服务,访问http://www.yourdomain2.com:8080则访问到内网机器上 8080 端口的服务。
转发 DNS 查询请求
这个示例通过简单配置 UDP 类型的代理转发 DNS 查询请求。
DNS 查询请求通常使用 UDP 协议,frp 支持对内网 UDP 服务的穿透,配置方式和 TCP 基本一致。
-
frps.ini 内容如下:
[common] bind_port = 7000 -
frpc.ini 内容如下:
[common] server_addr = x.x.x.x server_port = 7000 [dns] type = udp local_ip = 8.8.8.8 local_port = 53 remote_port = 6000这里反代了 Google 的 DNS 查询服务器的地址,仅仅用于测试 UDP 代理,并无实际意义。
-
分别启动 frps 和 frpc。
-
通过 dig 测试 UDP 包转发是否成功,预期会返回
www.baidu.com域名的解析结果。dig @x.x.x.x -p 6000 www.baidu.com
转发 Unix 域套接字
这个示例通过配置 Unix域套接字客户端插件来通过 TCP 端口访问内网的 Unix域套接字服务,例如 Docker Daemon。
-
frps.ini 内容如下:
[common] bind_port = 7000 -
frpc.ini 内容如下:
[common] server_addr = x.x.x.x server_port = 7000 [unix_domain_socket] type = tcp remote_port = 6000 plugin = unix_domain_socket plugin_unix_path = /var/run/docker.sock -
分别启动 frps 和 frpc。
-
通过 curl 命令查看 docker 版本信息
curl http://x.x.x.x:6000/version
对外提供简单的文件访问服务
这个示例通过配置 static_file 客户端插件来将本地文件暴露在公网上供其他人访问。
通过 static_file 插件可以对外提供一个简单的基于 HTTP 的文件访问服务。
-
frps.ini 内容如下:
[common] bind_port = 7000 -
frpc.ini 内容如下:
[common] server_addr = x.x.x.x server_port = 7000 [test_static_file] type = tcp remote_port = 6000 plugin = static_file # 要对外暴露的文件目录 plugin_local_path = /tmp/file # 用户访问 URL 中会被去除的前缀,保留的内容即为要访问的文件路径 plugin_strip_prefix = static plugin_http_user = abc plugin_http_passwd = abc -
分别启动 frps 和 frpc。
-
通过浏览器访问
http://x.x.x.x:6000/static/来查看位于/tmp/file目录下的文件,会要求输入已设置好的用户名和密码。
为本地 HTTP 服务启用 HTTPS
通过 https2http 插件可以让本地 HTTP 服务转换成 HTTPS 服务对外提供。
-
frps.ini 内容如下:
[common] bind_port = 7000 -
frpc.ini 内容如下:
[common] server_addr = x.x.x.x server_port = 7000 [test_htts2http] type = https custom_domains = test.yourdomain.com plugin = https2http plugin_local_addr = 127.0.0.1:80 # HTTPS 证书相关的配置 plugin_crt_path = ./server.crt plugin_key_path = ./server.key plugin_host_header_rewrite = 127.0.0.1 plugin_header_X-From-Where = frp -
分别启动 frps 和 frpc。
-
通过浏览器访问
https://test.yourdomain.com。
安全地暴露内网服务
这个示例将会创建一个只有自己能访问到的 SSH 服务代理。
对于某些服务来说如果直接暴露于公网上将会存在安全隐患。
使用 stcp(secret tcp) 类型的代理可以避免让任何人都能访问到要穿透的服务,但是访问者也需要运行另外一个 frpc 客户端。
-
frps.ini 内容如下:
[common] bind_port = 7000 -
在需要暴露到内网的机器上部署 frpc,且配置如下:
[common] server_addr = x.x.x.x server_port = 7000 [secret_ssh] type = stcp # 只有 sk 一致的用户才能访问到此服务 sk = abcdefg local_ip = 127.0.0.1 local_port = 22 -
在想要访问内网服务的机器上也部署 frpc,且配置如下:
[common] server_addr = x.x.x.x server_port = 7000 [secret_ssh_visitor] type = stcp # stcp 的访问者 role = visitor # 要访问的 stcp 代理的名字 server_name = secret_ssh sk = abcdefg # 绑定本地端口用于访问 SSH 服务 bind_addr = 127.0.0.1 bind_port = 6000 -
通过 SSH 访问内网机器,假设用户名为 test:
ssh -oPort=6000 test@127.0.0.1
点对点内网穿透
这个示例将会演示一种不通过服务器中转流量的方式来访问内网服务。
frp 提供了一种新的代理类型 xtcp 用于应对在希望传输大量数据且流量不经过服务器的场景。
使用方式同 stcp 类似,需要在两边都部署上 frpc 用于建立直接的连接。
目前处于开发的初级阶段,并不能穿透所有类型的 NAT 设备,所以穿透成功率较低。穿透失败时可以尝试 stcp 的方式。
-
frps.ini 内容如下,需要额外配置监听一个 UDP 端口用于支持该类型的客户端:
[common] bind_port = 7000 bind_udp_port = 7000 -
在需要暴露到内网的机器上部署 frpc,且配置如下:
[common] server_addr = x.x.x.x server_port = 7000 [p2p_ssh] type = xtcp # 只有 sk 一致的用户才能访问到此服务 sk = abcdefg local_ip = 127.0.0.1 local_port = 22 -
在想要访问内网服务的机器上也部署 frpc,且配置如下:
[common] server_addr = x.x.x.x server_port = 7000 [p2p_ssh_visitor] type = xtcp # xtcp 的访问者 role = visitor # 要访问的 xtcp 代理的名字 server_name = p2p_ssh sk = abcdefg # 绑定本地端口用于访问 ssh 服务 bind_addr = 127.0.0.1 bind_port = 6000 -
通过 SSH 访问内网机器,假设用户名为 test:
ssh -oPort=6000 test@127.0.0.1
参考
服务端配置
frp 服务端详细配置说明。
基础配置
| 参数 | 类型 | 说明 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|
| bind_addr | string | 服务端监听地址 | 0.0.0.0 | ||
| bind_port | int | 服务端监听端口 | 7000 | 接收 frpc 的连接 | |
| bind_udp_port | int | 服务端监听 UDP 端口 | 0 | 用于辅助创建 P2P 连接 | |
| kcp_bind_port | int | 服务端监听 KCP 协议端口 | 0 | 用于接收采用 KCP 连接的 frpc | |
| proxy_bind_addr | string | 代理监听地址 | 同 bind_addr | 可以使代理监听在不同的网卡地址 | |
| log_file | string | 日志文件地址 | ./frps.log | 如果设置为 console,会将日志打印在标准输出中 | |
| log_level | string | 日志等级 | info | trace, debug, info, warn, error | |
| log_max_days | int | 日志文件保留天数 | 3 | ||
| disable_log_color | bool | 禁用标准输出中的日志颜色 | false | ||
| detailed_errors_to_client | bool | 服务端返回详细错误信息给客户端 | true | ||
| heart_beat_timeout | int | 服务端和客户端心跳连接的超时时间 | 90 | 单位:秒 | |
| user_conn_timeout | int | 用户建立连接后等待客户端响应的超时时间 | 10 | 单位:秒 | |
| udp_packet_size | int | 代理 UDP 服务时支持的最大包长度 | 1500 | 服务端和客户端的值需要一致 | |
| tls_cert_file | string | TLS 服务端证书文件路径 | |||
| tls_key_file | string | TLS 服务端密钥文件路径 | |||
| tls_trusted_ca_file | string | TLS CA 证书路径 |
权限验证
| 参数 | 类型 | 说明 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|
| authentication_method | string | 鉴权方式 | token | token, oidc | |
| authenticate_heartbeats | bool | 开启心跳消息鉴权 | false | ||
| authenticate_new_work_conns | bool | 开启建立工作连接的鉴权 | false | ||
| token | string | 鉴权使用的 token 值 | 客户端需要设置一样的值才能鉴权通过 | ||
| oidc_issuer | string | oidc_issuer | |||
| oidc_audience | string | oidc_audience | |||
| oidc_skip_expiry_check | bool | oidc_skip_expiry_check | |||
| oidc_skip_issuer_check | bool | oidc_skip_issuer_check |
管理配置
| 参数 | 类型 | 说明 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|
| allow_ports | string | 允许代理绑定的服务端端口 | 格式为 1000-2000,2001,3000-4000 | ||
| max_pool_count | int | 最大连接池大小 | 5 | ||
| max_ports_per_client | int | 限制单个客户端最大同时存在的代理数 | 0 | 0 表示没有限制 | |
| tls_only | bool | 只接受启用了 TLS 的客户端连接 | false |
Dashboard, 监控
| 参数 | 类型 | 说明 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|
| dashboard_addr | string | 启用 Dashboard 监听的本地地址 | 0.0.0.0 | ||
| dashboard_port | int | 启用 Dashboard 监听的本地端口 | 0 | ||
| dashboard_user | string | HTTP BasicAuth 用户名 | |||
| dashboard_pwd | string | HTTP BasicAuth 密码 | |||
| enable_prometheus | bool | 是否提供 Prometheus 监控接口 | false | 需要同时启用了 Dashboard 才会生效 | |
| asserts_dir | string | 静态资源目录 | Dashboard 使用的资源默认打包在二进制文件中,通过指定此参数使用自定义的静态资源 |
HTTP & HTTPS
| 参数 | 类型 | 说明 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|
| vhost_http_port | int | 为 HTTP 类型代理监听的端口 | 0 | 启用后才支持 HTTP 类型的代理,默认不启用 | |
| vhost_https_port | int | 为 HTTPS 类型代理监听的端口 | 0 | 启用后才支持 HTTPS 类型的代理,默认不启用 | |
| vhost_http_timeout | int | HTTP 类型代理在服务端的 ResponseHeader 超时时间 | 60 | ||
| subdomain_host | string | 二级域名后缀 | |||
| custom_404_page | string | 自定义 404 错误页面地址 |
TCPMUX
| 参数 | 类型 | 说明 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|
| tcpmux_httpconnect_port | int | 为 TCPMUX 类型代理监听的端口 | 0 | 启用后才支持 TCPMUX 类型的代理,默认不启用 |
客户端配置
frp 客户端的详细配置说明。
基础配置
| 参数 | 类型 | 说明 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|
| server_addr | string | 连接服务端的地址 | 0.0.0.0 | ||
| server_port | int | 连接服务端的端口 | 7000 | ||
| http_proxy | string | 连接服务端使用的代理地址 | 格式为 {protocol}://user:passwd@192.168.1.128:8080 protocol 目前支持 http、socks5、ntlm | ||
| log_file | string | 日志文件地址 | ./frpc.log | 如果设置为 console,会将日志打印在标准输出中 | |
| log_level | string | 日志等级 | info | trace, debug, info, warn, error | |
| log_max_days | int | 日志文件保留天数 | 3 | ||
| disable_log_color | bool | 禁用标准输出中的日志颜色 | false | ||
| pool_count | int | 连接池大小 | 0 | ||
| user | string | 用户名 | 设置此参数后,代理名称会被修改为 {user}.{proxyName},避免代理名称和其他用户冲突 | ||
| dns_server | string | 使用 DNS 服务器地址 | 默认使用系统配置的 DNS 服务器,指定此参数可以强制替换为自定义的 DNS 服务器地址 | ||
| login_fail_exit | bool | 第一次登陆失败后是否退出 | true | ||
| protocol | string | 连接服务端的通信协议 | tcp | tcp, kcp, websocket | |
| tls_enable | bool | 启用 TLS 协议加密连接 | false | ||
| tls_cert_file | string | TLS 客户端证书文件路径 | |||
| tls_key_file | string | TLS 客户端密钥文件路径 | |||
| tls_trusted_ca_file | string | TLS CA 证书路径 | |||
| tls_server_name | string | TLS Server 名称 | 为空则使用 server_addr | ||
| heartbeat_interval | int | 向服务端发送心跳包的间隔时间 | 30 | ||
| heartbeat_timeout | int | 和服务端心跳的超时时间 | 90 | ||
| udp_packet_size | int | 代理 UDP 服务时支持的最大包长度 | 1500 | 服务端和客户端的值需要一致 | |
| start | string | 指定启用部分代理 | 当配置了较多代理,但是只希望启用其中部分时可以通过此参数指定,默认为全部启用 |
权限验证
| 参数 | 类型 | 说明 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|
| authentication_method | string | 鉴权方式 | token | token, oidc | 需要和服务端一致 |
| authenticate_heartbeats | bool | 开启心跳消息鉴权 | false | 需要和服务端一致 | |
| authenticate_new_work_conns | bool | 开启建立工作连接的鉴权 | false | 需要和服务端一致 | |
| token | string | 鉴权使用的 token 值 | 需要和服务端设置一样的值才能鉴权通过 | ||
| oidc_client_id | string | oidc_client_id | |||
| oidc_client_secret | string | oidc_client_secret | |||
| oidc_audience | string | oidc_audience | |||
| oidc_token_endpoint_url | string | oidc_token_endpoint_url |
UI
| 参数 | 类型 | 说明 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|
| admin_addr | string | 启用 AdminUI 监听的本地地址 | 0.0.0.0 | ||
| admin_port | int | 启用 AdminUI 监听的本地端口 | 0 | ||
| admin_user | string | HTTP BasicAuth 用户名 | |||
| admin_pwd | string | HTTP BasicAuth 密码 | |||
| asserts_dir | string | 静态资源目录 | AdminUI 使用的资源默认打包在二进制文件中,通过指定此参数使用自定义的静态资源 |
代理配置
frp 代理的详细配置说明。
通用配置
通用配置是指不同类型的代理共同使用的一些配置参数。
基础配置
| 参数 | 类型 | 说明 | 是否必须 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|---|
| type | string | 代理类型 | 是 | tcp | tcp, udp, http, https, stcp, sudp, xtcp, tcpmux | |
| use_encryption | bool | 是否启用加密功能 | 否 | false | 启用后该代理和服务端之间的通信内容都会被加密传输 | |
| use_compression | bool | 是否启用压缩功能 | 否 | false | 启用后该代理和服务端之间的通信内容都会被压缩传输 | |
| proxy_protocol_version | string | 启用 proxy protocol 协议的版本 | 否 | v1, v2 | 如果启用,则 frpc 和本地服务建立连接后会发送 proxy protocol 的协议,包含了原请求的 IP 地址和端口等内容 | |
| bandwidth_limit | string | 设置单个 proxy 的带宽限流 | 否 | 单位为 MB 或 KB,0 表示不限制,如果启用,会作用于对应的 frpc |
本地服务配置
local_ip 和 plugin 的配置必须配置一个,且只能生效一个,如果配置了 plugin,则 local_ip 配置无效。
| 参数 | 类型 | 说明 | 是否必须 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|---|
| local_ip | string | 本地服务 IP | 是 | 127.0.0.1 | 需要被代理的本地服务的 IP 地址,可以为所在 frpc 能访问到的任意 IP 地址 | |
| local_port | int | 本地服务端口 | 是 | 配合 local_ip | ||
| plugin | string | 客户端插件名称 | 否 | 见客户端插件的功能说明 | 用于扩展 frpc 的能力,能够提供一些简单的本地服务,如果配置了 plugin,则 local_ip 和 local_port 无效,两者只能配置一个 | |
| plugin_params | map | 客户端插件参数 | 否 | map 结构,key 需要都以 "plugin_" 开头,每一个 plugin 需要的参数也不一样,具体见客户端插件参数中的内容 |
负载均衡和健康检查
| 参数 | 类型 | 说明 | 是否必须 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|---|
| group | string | 负载均衡分组名称 | 否 | 用户请求会以轮询的方式发送给同一个 group 中的代理 | ||
| group_key | string | 负载均衡分组密钥 | 否 | 用于对负载均衡分组进行鉴权,group_key 相同的代理才会被加入到同一个分组中 | ||
| health_check_type | string | 健康检查类型 | 否 | tcp,http | 配置后启用健康检查功能,tcp 是连接成功则认为服务健康,http 要求接口返回 2xx 的状态码则认为服务健康 | |
| health_check_timeout_s | int | 健康检查超时时间(秒) | 否 | 3 | 执行检查任务的超时时间 | |
| health_check_max_failed | int | 健康检查连续错误次数 | 否 | 1 | 连续检查错误多少次认为服务不健康 | |
| health_check_interval_s | int | 健康检查周期(秒) | 否 | 10 | 每隔多长时间进行一次健康检查 | |
| health_check_url | string | 健康检查的 HTTP 接口 | 否 | 如果 health_check_type 类型是 http,则需要配置此参数,指定发送 http 请求的 url,例如 "/health" |
TCP
| 参数 | 类型 | 说明 | 是否必须 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|---|
| remote_port | int | 服务端绑定的端口 | 是 | 用户访问此端口的请求会被转发到 local_ip:local_port |
UDP
| 参数 | 类型 | 说明 | 是否必须 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|---|
| remote_port | int | 服务端绑定的端口 | 是 | 用户访问此端口的请求会被转发到 local_ip:local_port |
HTTP
custom_domains 和 subdomain 必须要配置其中一个,两者可以同时生效。
| 参数 | 类型 | 说明 | 是否必须 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|---|
| custom_domains | []string | 服务器绑定自定义域名 | 是(和 subdomain 两者必须配置一个) | 用户通过 vhost_http_port 访问的 HTTP 请求如果 Host 在 custom_domains 配置的域名中,则会被路由到此代理配置的本地服务 | ||
| subdomain | string | 自定义子域名 | 是(和 custom_domains 两者必须配置一个) | 和 custom_domains 作用相同,但是只需要指定子域名前缀,会结合服务端的 subdomain_host 生成最终绑定的域名 | ||
| locations | []string | URL 路由配置 | 否 | 采用最大前缀匹配的规则,用户请求匹配响应的 location 配置,则会被路由到此代理 | ||
| http_user | string | 用户名 | 否 | 如果配置此参数,暴露出去的 HTTP 服务需要采用 Basic Auth 的鉴权才能访问 | ||
| http_pwd | string | 密码 | 否 | 结合 http_user 使用 | ||
| host_header_rewrite | string | 替换 Host header | 否 | 替换发送到本地服务 HTTP 请求中的 Host 字段 | ||
| headers | map | 替换 header | 否 | map 中的 key 是要替换的 header 的 key,value 是替换后的内容 |
HTTPS
custom_domains 和 subdomain 必须要配置其中一个,两者可以同时生效。
| 参数 | 类型 | 说明 | 是否必须 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|---|
| custom_domains | []string | 服务器绑定自定义域名 | 是(和 subdomain 两者必须配置一个) | 用户通过 vhost_http_port 访问的 HTTP 请求如果 Host 在 custom_domains 配置的域名中,则会被路由到此代理配置的本地服务 | ||
| subdomain | string | 自定义子域名 | 是(和 custom_domains 两者必须配置一个) | 和 custom_domains 作用相同,但是只需要指定子域名前缀,会结合服务端的 subdomain_host 生成最终绑定的域名 |
STCP
| 参数 | 类型 | 说明 | 是否必须 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|---|
| role | string | 角色 | 是 | server | server,visitor | server 表示服务端,visitor 表示访问端 |
| sk | string | 密钥 | 是 | 服务端和访问端的密钥需要一致,访问端才能访问到服务端 |
SUDP
| 参数 | 类型 | 说明 | 是否必须 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|---|
| role | string | 角色 | 是 | server | server,visitor | server 表示服务端,visitor 表示访问端 |
| sk | string | 密钥 | 是 | 服务端和访问端的密钥需要一致,访问端才能访问到服务端 |
XTCP
| 参数 | 类型 | 说明 | 是否必须 | 默认值 | 可选值 | 备注 |
|---|---|---|---|---|---|---|
| role | string | 角色 | 是 | server | server,visitor | server 表示服务端,visitor 表示访问端 |
| sk | string | 密钥 | 是 | 服务端和访问端的密钥需要一致,访问端才能访问到服务端 |
ubuntu 防止SSH暴力登录攻击
最近观察服务器的认证日志,发现有些国外的
IP地址,多次尝试破解服务器的密码进行登录。于是希望能将多次尝试SSH登录失败的IP阻止掉。
查看日志文件:
sudo tail -f /var/log/auth.log
看到很多如下的日志:

来统计一下有多少人在暴力破解 root 密码
sudo grep "Failed password for root" /var/log/auth.log | awk '{print $11}' | sort | uniq -c | sort -nr | more
3579 111.198.159.85
1185 111.229.204.86
457 121.89.198.64
109 112.85.236.98
106 36.94.17.242
99 45.141.84.126
89 129.28.163.90
83 111.231.87.10
77 64.225.53.232
77 122.155.202.93
72 64.225.126.22
72 113.57.170.50
72 103.117.120.47
71 45.232.244.5
71 138.197.149.97
70 134.175.154.93
67 159.65.100.44
67 120.131.13.186
67 104.248.205.67
64 152.32.222.192
61 150.136.40.83
59 188.170.13.225
59 178.128.14.102
如果已经禁用了 root 登录,则看一下暴力猜用户名的统计信息
sudo grep "Failed password for invalid user" /var/log/auth.log | awk '{print $13}' | sort | uniq -c | sort -nr | more
1812 111.198.159.85
645 111.229.204.86
275 45.141.84.126
85 36.94.17.242
85 112.85.236.98
56 111.231.87.10
55 172.103.3.143
52 211.253.26.117
51 129.28.163.90
50 134.175.154.93
为了防范于未然,我们可以做些配置,让服务器更加安全。
下面的三个方法,可以完全使用,也可以部分使用。一般建议使用其中的第一条跟第三条。
- 修改
SSH端口,禁止root登陆
修改 /etc/ssh/sshd_config 文件
sudo vim /etc/ssh/sshd_config
Port 1234 # 一个别人猜不到的端口号
PermitRootLogin no
sudo service sshd restart
- 禁用密码登陆,使用
RSA私钥登录
如果服务器只允许使用私钥登录的,但是如果想在别的电脑上临时 SSH 上来,又没带私钥文件的情况下,就很麻烦。所以还是保留密码验证登录。不管怎样,这一条还是先列出来
# 在客户端生成密钥
ssh-keygen -t rsa
# 把公钥拷贝至服务器
ssh-copy-id -i .ssh/id_rsa.pub server
# 也可以手动将.shh/id_rsa.pub拷贝至服务器用户目录的.ssh中,记得修改访问权限
# $ scp .shh/id_rsa.pub server:~/.ssh
# 在服务器中
cd ./.ssh/
mv id_rsa.pub authorized_keys
chmod 400 authorized_keys
vim /etc/ssh/sshd_config
RSAAuthentication yes #RSA认证
PubkeyAuthentication yes #开启公钥验证
AuthorizedKeysFile .ssh/authorized_keys #验证文件路径
PasswordAuthentication no #禁止密码认证
PermitEmptyPasswords no #禁止空密码
UsePAM no #禁用PAM
# 最后保存,重启
sudo service sshd restart
- 安装
denyhosts
denyhosts 是 Python 语言写的一个程序,它会分析 sshd 的日志文件,当发现重复的失败登录时就会记录 IP 到 /etc/hosts.deny 文件,从而达到自动屏 IP 的功能。现今 denyhosts 在各个发行版软件仓库里都有。
注意在 ubuntu 16.04 系统上,如果通过远程的 SSH 登录到服务器上执行安装命令的话,会由于默认情况下 RESET_ON_SUCCESS = yes #如果一个ip登陆成功后,失败的登陆计数是否重置为0 这部分,默认情况下是关闭的。而如果恰好我们又出现自己输入的错误密码错误累计次数超过 5 次的情况(即使后面有成功登录的记录也不行),会导致我们自己当前登录的地址也被阻止的情况。这种情况发生之后,会导致我们自己无法控制服务器(这个阻塞是在 iptables 层阻塞的,如果要恢复,在 iptables 中删除已经添加的记录才可以)。解决办法就是换一个新的 IP 地址登录服务器,然后修改 RESET_ON_SUCCESS 这个参数,并重启 denyhosts 服务。如果是阿里云或者腾讯云的服务器,可以尝试从他们网站上提供的网页版本的 Shell 进行操作。
对于 ubuntu 16.04 系统,建议使用如下方式进行安装:
#创建执行脚本
touch ~/install.sh
#创建执行安装命令,整个过程不中断连续执行,如果不使用脚本,执行到这里,可能SSH就已经被阻断了
#安装完成后,denyhosts的服务就已经开始运行了,此时可能已经设置了iptables了
echo "sudo apt-get install denyhosts" >> ~/install.sh
#创建修改配置文件的命令
echo "sudo sed -i 's/^#RESET_ON_SUCCESS/RESET_ON_SUCCESS/g' /etc/denyhosts.conf" >> ~/install.sh
#创建重启服务的命令
echo "sudo service denyhosts restart" >> ~/install.sh
#执行我们刚刚的安装脚本
sudo bash ~/install.sh
默认配置就能很好的工作,如要个性化设置可以修改 /etc/denyhosts.conf
sudo vim /etc/denyhosts.conf
SECURE_LOG = /var/log/auth.log #ssh 日志文件,它是根据这个文件来判断的。
HOSTS_DENY = /etc/hosts.deny #控制用户登陆的文件
PURGE_DENY = #过多久后清除已经禁止的,空表示永远不解禁
BLOCK_SERVICE = sshd #禁止的服务名,如还要添加其他服务,只需添加逗号跟上相应的服务即可
DENY_THRESHOLD_INVALID = 5 #允许无效用户失败的次数
DENY_THRESHOLD_VALID = 10 #允许普通用户登陆失败的次数
DENY_THRESHOLD_ROOT = 1 #允许root登陆失败的次数
DENY_THRESHOLD_RESTRICTED = 1
WORK_DIR = /var/lib/denyhosts #运行目录
SUSPICIOUS_LOGIN_REPORT_ALLOWED_HOSTS=YES
HOSTNAME_LOOKUP=YES #是否进行域名反解析
LOCK_FILE = /var/run/denyhosts.pid #程序的进程ID
ADMIN_EMAIL = root@localhost #管理员邮件地址,它会给管理员发邮件
SMTP_HOST = localhost
SMTP_PORT = 25
SMTP_FROM = DenyHosts <nobody@localhost>
SMTP_SUBJECT = DenyHosts Report
AGE_RESET_VALID=5d #用户的登录失败计数会在多久以后重置为0,(h表示小时,d表示天,m表示月,w表示周,y表示年)
AGE_RESET_ROOT=25d
AGE_RESET_RESTRICTED=25d
AGE_RESET_INVALID=10d
RESET_ON_SUCCESS = yes #如果一个ip登陆成功后,失败的登陆计数是否重置为0
DAEMON_LOG = /var/log/denyhosts #自己的日志文件
DAEMON_SLEEP = 30s #当以后台方式运行时,每读一次日志文件的时间间隔。
DAEMON_PURGE = 1h #当以后台方式运行时,清除机制在 HOSTS_DENY 中终止旧条目的时间间隔,这个会影响PURGE_DENY的间隔。
查看 /etc/hosts.deny 发现里面已经有 3 条记录。
sudo cat /etc/hosts.deny | wc -l
3
目前 ubuntu 16.04 系统源里的 denyhosts 存在一个 BUG ,就是系统重启之后, iptables 中的拦截设置没有恢复。具体的讨论以及描述,参考 Iptables not persistent,代码应该已经增加了,目前还没合并到主分支。
参考链接
- VPS 防止 SSH 暴力登录尝试攻击
- Meaning of “Connection closed by xxx [preauth]” in sshd logs
- denyhosts keeps adding back my IP
- 如何使用 fail2ban 防御 SSH 服务器的暴力破解攻击
AES五种加密模式(CBC、ECB、CTR、OCF、CFB)
AES五种加密模式(CBC、ECB、CTR、OCF、CFB)
分组密码有五种工作体制:
- 电码本模式(Electronic Codebook Book (ECB));
- 密码分组链接模式(Cipher Block Chaining (CBC));
- 计算器模式(Counter (CTR));
- 密码反馈模式(Cipher FeedBack (CFB));
- 输出反馈模式(Output FeedBack (OFB))。
以下逐一介绍一下:
1.电码本模式(Electronic Codebook Book (ECB)
这种模式是将整个明文分成若干段相同的小段,然后对每一小段进行加密。
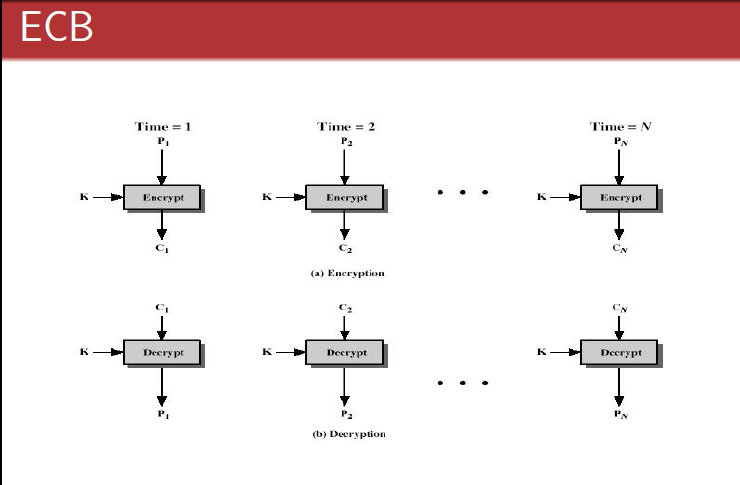
2.密码分组链接模式(Cipher Block Chaining (CBC))
这种模式是先将明文切分成若干小段,然后每一小段与初始块或者上一段的密文段进行异或运算后,再与密钥进行加密。
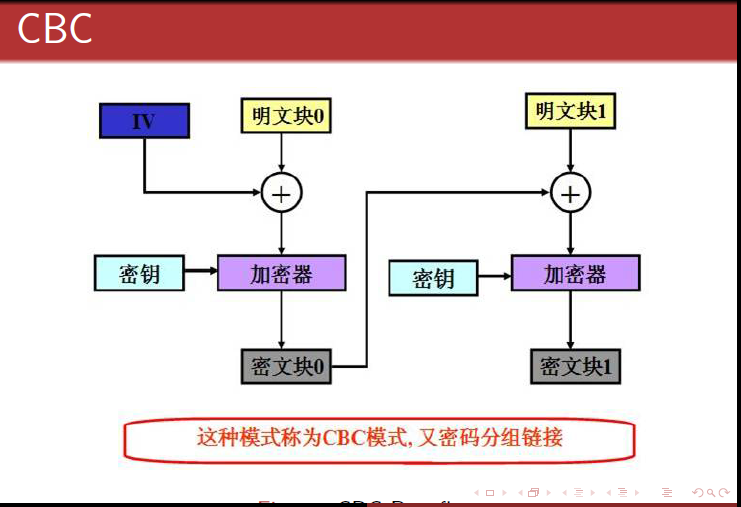
3.计算器模式(Counter (CTR))
计算器模式不常见,在CTR模式中, 有一个自增的算子,这个算子用密钥加密之后的输出和明文异或的结果得到密文,相当于一次一密。这种加密方式简单快速,安全可靠,而且可以并行加密,但是在计算器不能维持很长的情况下,密钥只能使用一次。CTR的示意图如下所示:
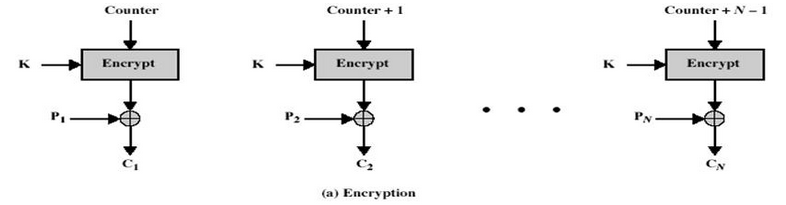
4.密码反馈模式(Cipher FeedBack (CFB))
这种模式较复杂。

5.输出反馈模式(Output FeedBack (OFB))
这种模式较复杂。
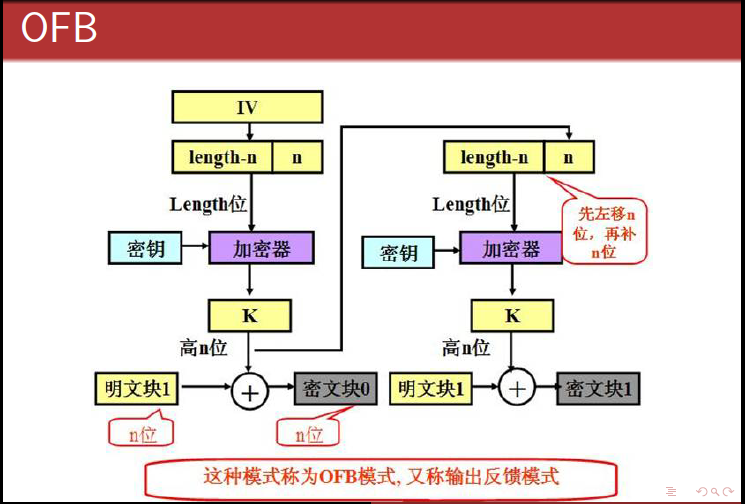
以下附上C++源代码:
/**
*@autho stardust
*@time 2013-10-10
*@param 实现AES五种加密模式的测试
*/
#include <iostream>
using namespace std;
//加密编码过程函数,16位1和0
int dataLen = 16; //需要加密数据的长度
int encLen = 4; //加密分段的长度
int encTable[4] = {1,0,1,0}; //置换表
int data[16] = {1,0,0,1,0,0,0,1,1,1,1,1,0,0,0,0}; //明文
int ciphertext[16]; //密文
//切片加密函数
void encode(int arr[])
{
for(int i=0;i<encLen;i++)
{
arr[i] = arr[i] ^ encTable[i];
}
}
//电码本模式加密,4位分段
void ECB(int arr[])
{
//数据明文切片
int a[4][4];
int dataCount = 0; //位置变量
for(int k=0;k<4;k++)
{
for(int t=0;t<4;t++)
{
a[k][t] = data[dataCount];
dataCount++;
}
}
dataCount = 0;//重置位置变量
for(int i=0;i<dataLen;i=i+encLen)
{
int r = i/encLen;//行
int l = 0;//列
int encQue[4]; //编码片段
for(int j=0;j<encLen;j++)
{
encQue[j] = a[r][l];
l++;
}
encode(encQue); //切片加密
//添加到密文表中
for(int p=0;p<encLen;p++)
{
ciphertext[dataCount] = encQue[p];
dataCount++;
}
}
cout<<"ECB加密的密文为:"<<endl;
for(int t1=0;t1<dataLen;t1++) //输出密文
{
if(t1!=0 && t1%4==0)
cout<<endl;
cout<<ciphertext[t1]<<" ";
}
cout<<endl;
cout<<"---------------------------------------------"<<endl;
}
//CBC
//密码分组链接模式,4位分段
void CCB(int arr[])
{
//数据明文切片
int a[4][4];
int dataCount = 0; //位置变量
for(int k=0;k<4;k++)
{
for(int t=0;t<4;t++)
{
a[k][t] = data[dataCount];
dataCount++;
}
}
dataCount = 0;//重置位置变量
int init[4] = {1,1,0,0}; //初始异或运算输入
//初始异或运算
for(int i=0;i<dataLen;i=i+encLen)
{
int r = i/encLen;//行
int l = 0;//列
int encQue[4]; //编码片段
//初始化异或运算
for(int k=0;k<encLen;k++)
{
a[r][k] = a[r][k] ^ init[k];
}
//与Key加密的单切片
for(int j=0;j<encLen;j++)
{
encQue[j] = a[r][j];
}
encode(encQue); //切片加密
//添加到密文表中
for(int p=0;p<encLen;p++)
{
ciphertext[dataCount] = encQue[p];
dataCount++;
}
//变换初始输入
for(int t=0;t<encLen;t++)
{
init[t] = encQue[t];
}
}
cout<<"CCB加密的密文为:"<<endl;
for(int t1=0;t1<dataLen;t1++) //输出密文
{
if(t1!=0 && t1%4==0)
cout<<endl;
cout<<ciphertext[t1]<<" ";
}
cout<<endl;
cout<<"---------------------------------------------"<<endl;
}
//CTR
//计算器模式,4位分段
void CTR(int arr[])
{
//数据明文切片
int a[4][4];
int dataCount = 0; //位置变量
for(int k=0;k<4;k++)
{
for(int t=0;t<4;t++)
{
a[k][t] = data[dataCount];
dataCount++;
}
}
dataCount = 0;//重置位置变量
int init[4][4] = {{1,0,0,0},{0,0,0,1},{0,0,1,0},{0,1,0,0}}; //算子表
int l = 0; //明文切片表列
//初始异或运算
for(int i=0;i<dataLen;i=i+encLen)
{
int r = i/encLen;//行
int encQue[4]; //编码片段
//将算子切片
for(int t=0;t<encLen;t++)
{
encQue[t] = init[r][t];
}
encode(encQue); //算子与key加密
//最后的异或运算
for(int k=0;k<encLen;k++)
{
encQue[k] = encQue[k] ^ a[l][k];
}
l++;
//添加到密文表中
for(int p=0;p<encLen;p++)
{
ciphertext[dataCount] = encQue[p];
dataCount++;
}
}
cout<<"CTR加密的密文为:"<<endl;
for(int t1=0;t1<dataLen;t1++) //输出密文
{
if(t1!=0 && t1%4==0)
cout<<endl;
cout<<ciphertext[t1]<<" ";
}
cout<<endl;
cout<<"---------------------------------------------"<<endl;
}
//CFB
//密码反馈模式,4位分段
void CFB(int arr[])
{
//数据明文切片,切成2 * 8 片
int a[8][2];
int dataCount = 0; //位置变量
for(int k=0;k<8;k++)
{
for(int t=0;t<2;t++)
{
a[k][t] = data[dataCount];
dataCount++;
}
}
dataCount = 0; //恢复初始化设置
int lv[4] = {1,0,1,1}; //初始设置的位移变量
int encQue[2]; //K的高两位
int k[4]; //K
for(int i=0;i<2 * encLen;i++) //外层加密循环
{
//产生K
for(int vk=0;vk<encLen;vk++)
{
k[vk] = lv[vk];
}
encode(k);
for(int k2=0;k2<2;k2++)
{
encQue[k2] = k[k2];
}
//K与数据明文异或产生密文
for(int j=0;j<2;j++)
{
ciphertext[dataCount] = a[dataCount/2][j] ^ encQue[j];
dataCount++;
}
//lv左移变换
lv[0] = lv[2];
lv[1] = lv[3];
lv[2] = ciphertext[dataCount-2];
lv[3] = ciphertext[dataCount-1];
}
cout<<"CFB加密的密文为:"<<endl;
for(int t1=0;t1<dataLen;t1++) //输出密文
{
if(t1!=0 && t1%4==0)
cout<<endl;
cout<<ciphertext[t1]<<" ";
}
cout<<endl;
cout<<"---------------------------------------------"<<endl;
}
//OFB
//输出反馈模式,4位分段
void OFB(int arr[])
{
//数据明文切片,切成2 * 8 片
int a[8][2];
int dataCount = 0; //位置变量
for(int k=0;k<8;k++)
{
for(int t=0;t<2;t++)
{
a[k][t] = data[dataCount];
dataCount++;
}
}
dataCount = 0; //恢复初始化设置
int lv[4] = {1,0,1,1}; //初始设置的位移变量
int encQue[2]; //K的高两位
int k[4]; //K
for(int i=0;i<2 * encLen;i++) //外层加密循环
{
//产生K
for(int vk=0;vk<encLen;vk++)
{
k[vk] = lv[vk];
}
encode(k);
for(int k2=0;k2<2;k2++)
{
encQue[k2] = k[k2];
}
//K与数据明文异或产生密文
for(int j=0;j<2;j++)
{
ciphertext[dataCount] = a[dataCount/2][j] ^ encQue[j];
dataCount++;
}
//lv左移变换
lv[0] = lv[2];
lv[1] = lv[3];
lv[2] = encQue[0];
lv[3] = encQue[1];
}
cout<<"CFB加密的密文为:"<<endl;
for(int t1=0;t1<dataLen;t1++) //输出密文
{
if(t1!=0 && t1%4==0)
cout<<endl;
cout<<ciphertext[t1]<<" ";
}
cout<<endl;
cout<<"---------------------------------------------"<<endl;
}
void printData()
{
cout<<"以下示范AES五种加密模式的测试结果:"<<endl;
cout<<"---------------------------------------------"<<endl;
cout<<"明文为:"<<endl;
for(int t1=0;t1<dataLen;t1++) //输出密文
{
if(t1!=0 && t1%4==0)
cout<<endl;
cout<<data[t1]<<" ";
}
cout<<endl;
cout<<"---------------------------------------------"<<endl;
}
int main()
{
printData();
ECB(data);
CCB(data);
CTR(data);
CFB(data);
OFB(data);
return 0;
}